当数据库遇上流计算:流数据库的诞生!
数据库发展回顾
数据库作为现代软件系统的基石,人们对它的研究由来已久,虽然到目前为止数据库领域已经先后产生过四位图灵奖得主,但是今天它仍然是计算机科学中最具活力和创新的领域之一。自上世纪70 年代 Edgar F. Codd 提出关系模型以来,以 IBM SystemR 为原型的关系数据库迅速发展,并在众多行业应用中取得成功,甚至直到今天,关系数据库仍然是数据库市场的绝对主流。
随着进入 21 世纪以来,由于互联网的兴起和蓬勃发展,传统的关系数据库开始难以满足快速发展的互联网业务的需求。在这样的背景下,轰轰烈烈的 NoSQL 运动揭开序幕,开启了数据库系统从关系数据库的一枝独秀到多种数据库系统百花齐放、百家争鸣的时代。这期间诞生了非常多优秀的数据库系统,包括但不限于:
- 以 MongoDB, CouchDB 为代表的文档数据库
- 以 HBase, Cassandra 为代表的宽列数据库
- 以 Google Spanner 为代表的分布式强一致的关系数据库,包括其开源实现 CockroachDB, TiDB
- 以 Apache Druid, ClickHouse 为代表的基于列式存储的分析型数据库
- 以 InfluxDB, TimescaleDB 为代表的时序数据库
- 以 Elasticsearch 为代表的全文索引数据库
- 以 Neo4j 为代表的图数据库
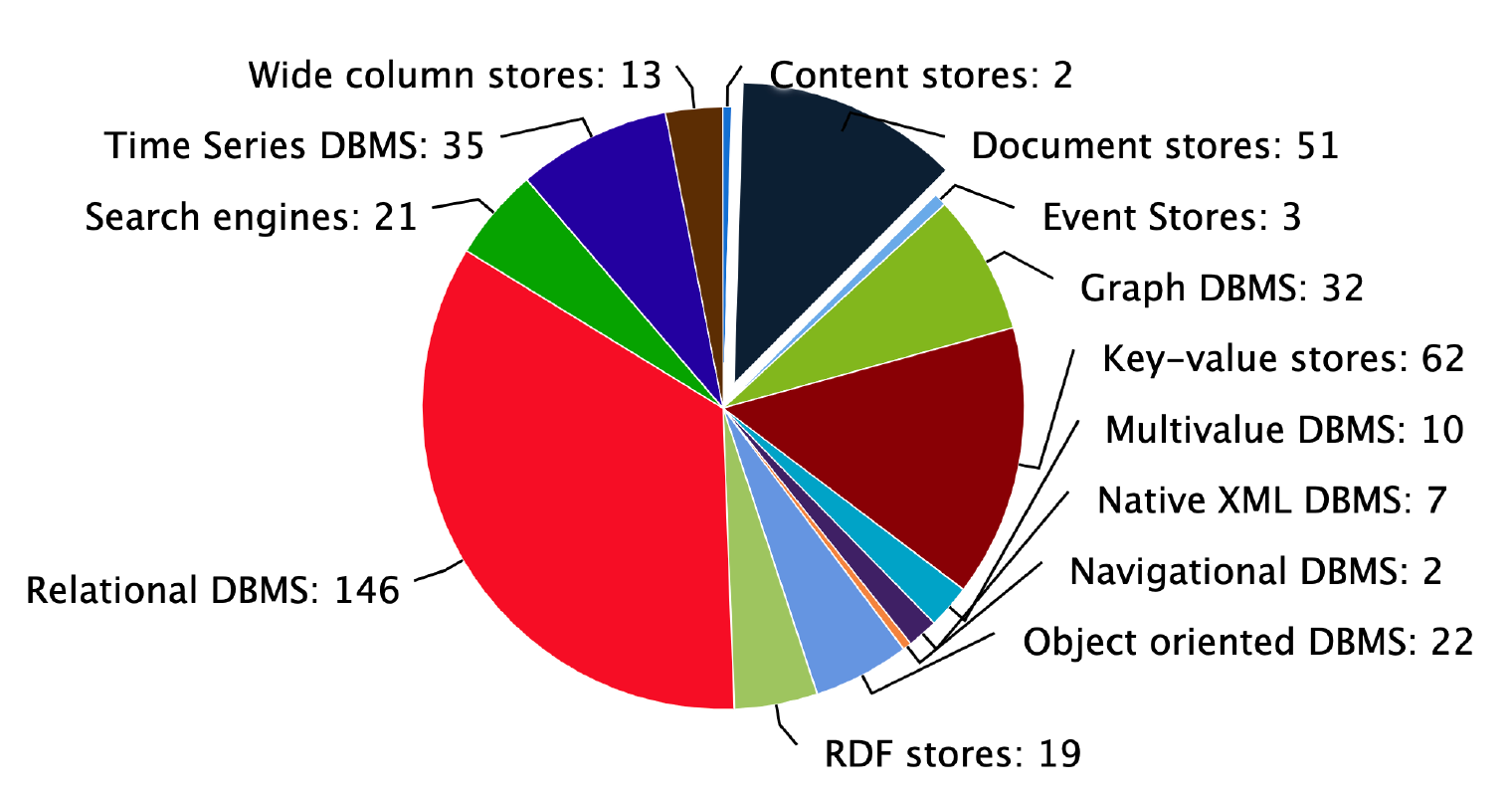
图 1: db-engines 上统计的各类数据库的数量
数据库系统持续发展和演进的背后,是近数十年来全球信息化浪潮下软件系统不断渗透到社会各个行业的过程,而与此同时, 不同行业、不同需求、不同场景也在不断地向数据库系统提出新的挑战。
目前为止,尚没有一个数据库系统能满足全行业、全场景的业务需求——甚至都很难满足一家公司或组织的全部需求。这是因为当前现实世界的业务需求日益复杂多样,往往在数据的存储模型、访问模式、存储的数据规模和时效、计算和分析能力,运维和部署成本等方面对数据库系统有不同的要求。 单一的数据库系统一般是基于某种特定的存储和计算模型而开发,因而一般只能在其目标场景下表现良好。
随着今后新兴行业的发展,新商业市场的开辟,新业务需求的涌现,必将催生新的数据库系统。 比如近年来 IoT 产业以及 AI 行业的兴起,直接导致了一批新的时序数据库和图数据库的诞生。
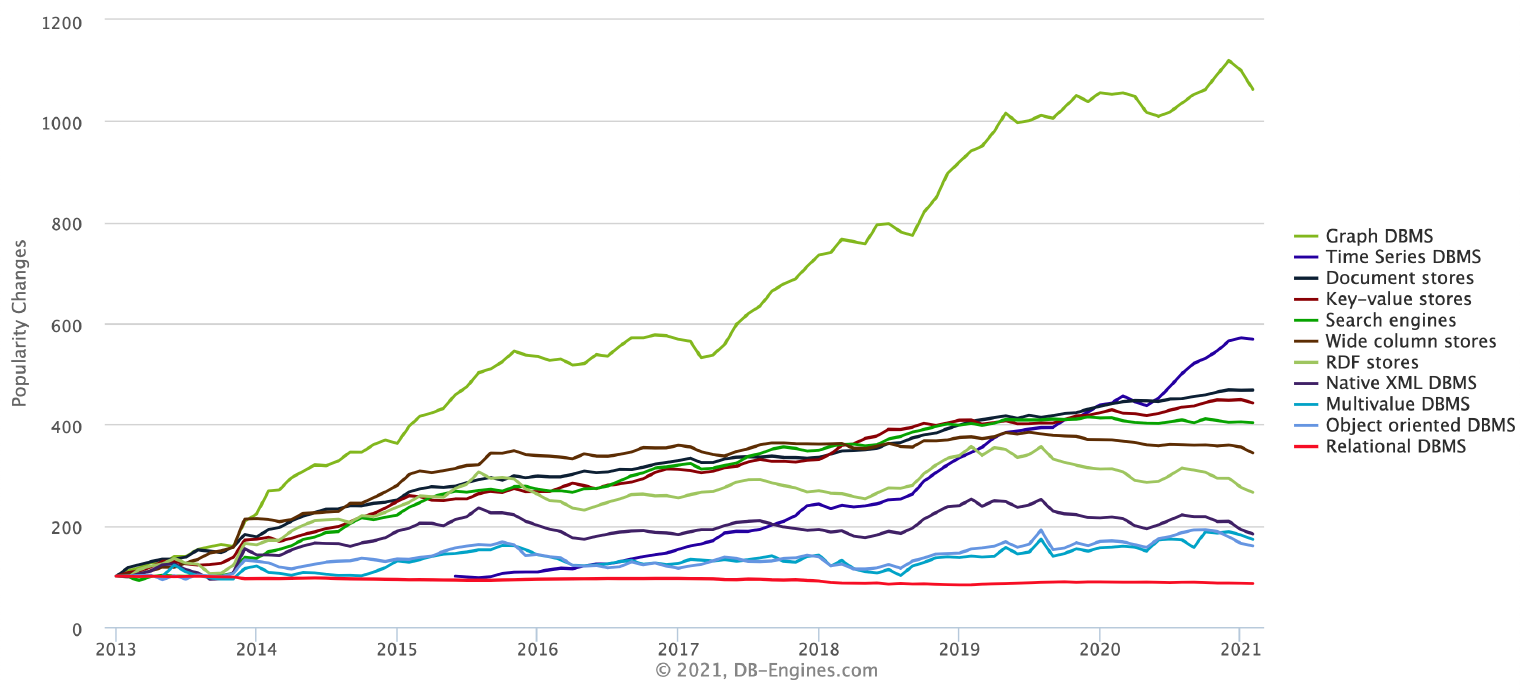
图 2: 2013 年以来各类数据库的流行度变化
新的数据存储和计算需求,始终是数据库系统发展的源动力。
实时流计算的兴起
随着计算机和网络技术的迅猛发展以及向各行业的不断渗透,如今数据的产生方式和产生来源相比以前都有了极大的丰富,比如:来自传感器的数据、网站上的用户活动数据、来自移动终端和智能设备的数据、金融市场的实时交易数据,各种监控程序产生的数据等等。 这些数据大多都是以连续的数据流的形式,从多种外部数据源持续不断地生成,在多数情况下,我们无法控制这些流数据到达的顺序和产生的速率。
根据国际知名分析机构 IDC 的研究报告1, 这种实时的流式数据占总体数据规模的比例正不断攀升,预计 2025 年能达到 30%。
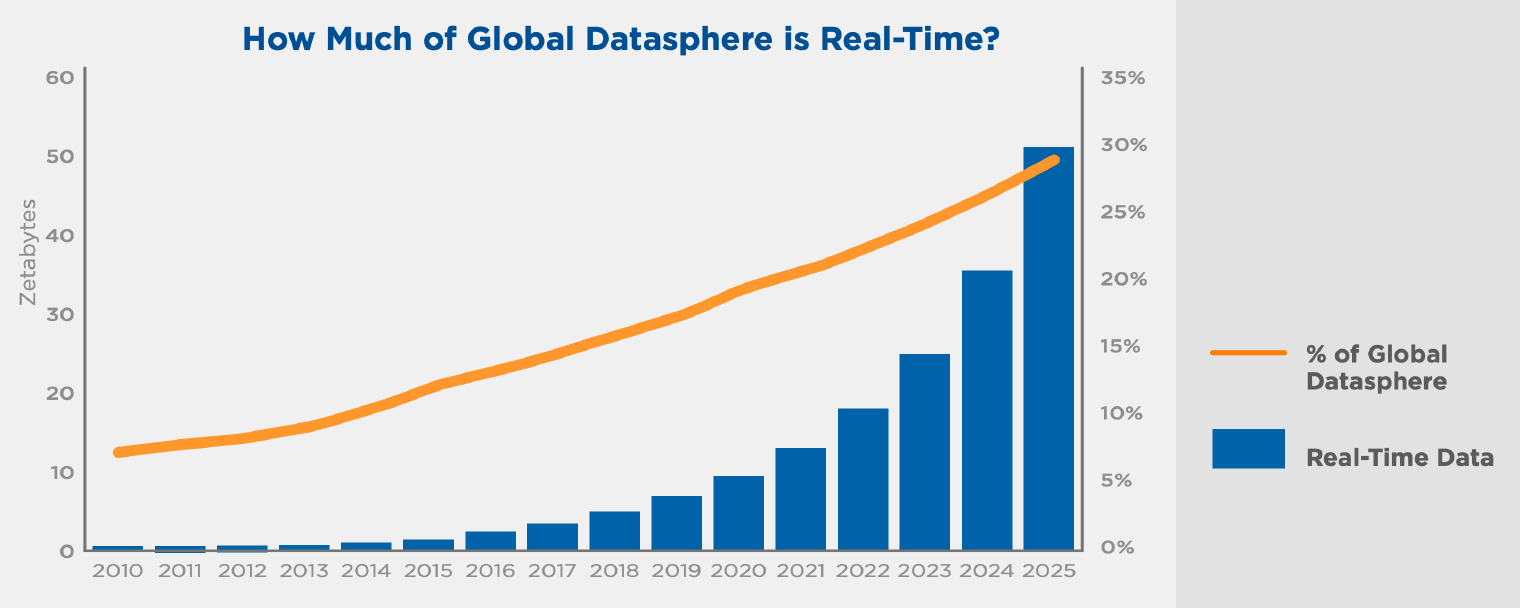
图 3: 实时数据的增长趋势 [1]
传统的数据处理系统通常是对已经存储在数据库系统或文件系统等其它存储系统中的完整静态数据集进行计算和分析,显然不适合这类持续生成的、无限的、动态的数据流。而且传统的批处理技术在数据生成到数据被处理之间通常会有比较长的时间间隔,然而在如今激烈竞争、复杂多变的商业环境下, 营销时机转瞬即逝,风险防控必须分秒必争,商业决策要求快速精准,因此数据的处理必须在更短的时间内得到结果,最好是能够做到实时处理。
在这种背景下,实时流处理技术开始在越来越多的场景下逐渐替代批处理技术,并在现代的数据分析技术栈中占据核心的位置。 流处理能够自然地对连续的数据流进行建模,与对静态数据的查询和分析不同,它能够随着新数据的到来实时地对计算结果进行更新,这使得「数据生成」-> 「获取数据洞察」-> 「采取行动」之间没有延迟, 从而让企业在激烈的市场竞争中始终保持主动和领先优势。
如今,流处理系统已经被各类企业和组织广泛部署和使用。所有主要的公有云厂商都提供了流式数据存储和实时处理的托管服务,比如:Amazon Kinesis,Google Dataflow 以及 Azure Stream Analytics。开源社区也涌现出一批流处理相关的软件系统,比如:Apache Storm,Apache Flink, Apache Beam等。同时在过去的几年里,也有越来越多的公司建立了自己内部的流数据平台,以便整个组织能够利用实时计算的力量,比如 Uber 的 AthenaX、Netflix 的 Keystone 平台以及Facebook 的 Turbine等。
数据库在流时代的挑战和机遇
尽管如今越来越多的企业和组织已经认识到流处理的巨大价值并开始应用和部署相关的系统,目前也有众多开源和商业的流处理软件可供选择,但要落地一整套流处理技术栈却绝非易事。 在实际实施的过程中就会发现当前的解决方案普遍存在着:复杂难用、部署和运维麻烦、上手门槛高、组件杂乱、API 不统一、迁移困难等问题, 比如当前基本的流处理方案都要涉及众多的分布式系统和组件,包括但不限于:
- 实时数据采集和捕获系统
- 实时数据存储系统
- 流计算引擎
- 下游的数据和应用系统
这不仅给开发和运维都带来了极大的挑战,而且引入的不同组件的越多,整个系统的可靠性就越低。同时这些方案中涉及的各个组件和系统不一定都是适合且高效的,而且彼此之间的集成往往也并非完美,因此通常很难满足企业的需求。比如流计算引擎要实现 exactly once 的处理语义和端到端的一致性,往往需要依赖流存储系统提供的支持,一般的集成方案很难达到这种要求。
一个有意思的现象在于,以往我们通常会将某种数据存储和计算的需求诉诸于某类数据库系统,然而 在面对实时数据流时,数据库系统却罕见的缺位了。 究其原因,我们认为一方面是一般的数据库系统很难满足大规模实时数据流的低延迟存储需求,这是由于其在维护其存储和索引结构上有相对较大的开销,造成较高的写入延时。
另外一个更重要的原因,可能和大家对数据库系统的「刻板印象」有关:认为数据库系统都工作在请求-响应的模型之下,是命令驱动式的,在这种模式下,计算(命令)是主动的,数据是被动的。然而 流处理的模式却与此完全相反,它是数据驱动的,即数据是主动的,计算是被动的,数据源源不断地流过计算,并持续更新计算的结果。 正是由于这种差异性,导致人们很难将流处理和数据库关联起来。
然而数据库系统真的全都如此吗?答案当然是否定的。已经有部分数据库不仅支持请求-响应式的命令驱动模型,也支持数据驱动的模型,比如: MongoDB 的 Change Streams 功能,RethinkDB 能够实时的推送数据,:MongoDB 的 Change Streams 功能,RethinkDB 能够实时的推送数据,TimescaleDB 的持续聚合功能。
更进一步, 我们完全可以期待用一款专业的数据库系统来解决我们对数据流管理的全部需求,比如通过熟悉的 SQL 语言来方便的进行流计算。
流数据库的诞生
事实上,面对实时数据流的存储和处理,我们需要的不是一堆零散的 ETL 工具、临时存储数据的消息中间件、孤立的流计算引擎,我们需要的仅仅是 一个专为流式数据设计的数据库系统,不妨称它为流数据库(streaming database)。
其实流数据库并非是一个我们今天发明的全新概念,甚至早在 1992 年的一篇发表在 SIGMOD 上的题为 Continuous queries over append-only database2 的论文里已经探索过它了。尽管这篇论文里并未明确提出流数据库这一概念,但我们的流数据库和论文的主要思想是一脉相承的。
不仅如此,我们认为, 不同于其它数据库系统将静态的数据集(表或文档等)作为基本的存储和处理单元,流数据库是以动态的连续数据流作为基本对象,以实时性作为主要特征的数据库。流数据库是数据库在流时代的重新架构和设计。
结语
数据库系统的发展已然进入一个全新的时代,是时候打破固有观念、创造属于流数据库的未来。在实时数据存储与计算需求与日俱增的时代背景下, 我们有理由相信,流数据库将大有可为。
在下篇推送中,我们将围绕流数据库的存储与各位继续深入探讨,让我们一起探寻一个高效可靠的流数据库应有的模样。
同时,我们也欢迎各位加入 EMQ,与我们共同发现和创造流数据库的无限可能。
