EMQ 物联网边缘流式数据处理软件 Kuiper 正式开源
全球领先的开源物联网软件提供商 EMQ (Github 项目) 于2019年10月23日正式开源了一个边缘端的超轻量级流式数据处理项目 EMQX Kuiper(以下简称 Kuiper)。随着 Kuiper 的发布,EMQ 将加快在物联网中间件领域的布局,从而形成从消息接入到数据处理,从边缘到云端的物联网中间件软件全领域覆盖。
物联网边缘计算新需求
2019 年作为 5G 商用元年,随着 5G 部署的深入,边缘计算也已经日渐流行。边缘计算通过在靠近接入网的机房增加计算能力,可以,
- 大幅降低业务时延
- 减少对网络的带宽压力,降低传输成本
- 减少在云端的数据存储成本
- 提高内容分发效率提升用户体验
物联网边缘计算很大一部分指的是流数据的处理,所谓流数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下,流数据可被视为一个随时间延续而无限增长的动态数据集合。流式数据处理可以帮助用户实时了解系统设备的状态,并对异常情况作出快速响应。在边缘端的计算资源(CPU,内存等)不像在云端丰富,因此传统的流式数据处理框架类似于 Apache Storm 或者 Apache Flink 等,由于其安装包过大,或者部署结构与过程过于复杂,运行时的高消耗等原因,并不适合于在这些资源受限的边缘设备(工控机、网关,或者配置不高的 X86 服务器等设备)上运行。而 EMQ 开源的 Kuiper 就是为了解决在物联网边缘设备上的这些问题。
Kuiper 特点
- 轻量级:安装包约 7MB左右;不依赖于第三方的库与运行时,下载解压后即可运行,安装和使用非常方便
- 跨操作系统支持:目前可以运行在 Linux 和 Mac 上,后续版本已规划会支持 Windows 操作系统
- 使用简单,快速应对敏捷业务变化:用户可以通过写 SQL 来实现业务处理;如果业务有变化,只需更新相关的 SQL 语句即可,而无需进行复杂的应用开发和部署
- 内置支持 MQTT 消息的处理:作为物联网领域的事实协议标准,Kuiper 内置了对接 EMQX 等 MQTT 消息服务器,实现对来自于物联网消息处理的无缝对接
- 可扩展性:Kuiper 定义了扩展接口,后续版本已经规划扩展实现不同消息源处理和处理后数据的沉淀(sink)
- 可管理性:Kuiper 定义了管理接口,后续版本已经规划可以通过 REST API 来实现这些业务规则的定义和管理等操作
Kuiper 应用场景
Kuiper 可以应用在各类边缘计算的场景中,典型应用场景包括,
- 车间的工业网关:实时分析来自于生产线的数据,并将分析结果推送至云端。车间本地可视化系统,或者远程监控系统可以查看生产线的实时状态
- 车联网车机:实时分析汽车总线的数据,经过分析将有价值的数据推送至云端或者本地存储,车载系统或者用户的手机应用可以实时查看汽车的状态
- 智能家居网关:通过实时分析家居采集的各类数据,将重要的结果通过本地显示设备,或者通过云端发送给用户的手机应用,实现对家庭设备的即时状态管理与控制
以上各类应用场景很好体现了边缘计算的价值:实时本地数据处理,提升用户体验;在本地数据处理,还提高了数据安全性,保护个人隐私;节省网络带宽和云端存储成本。Kuiper 可以运行在这些计算资源不足的边缘设备上,低成本地实现边缘端的流式数据处理。
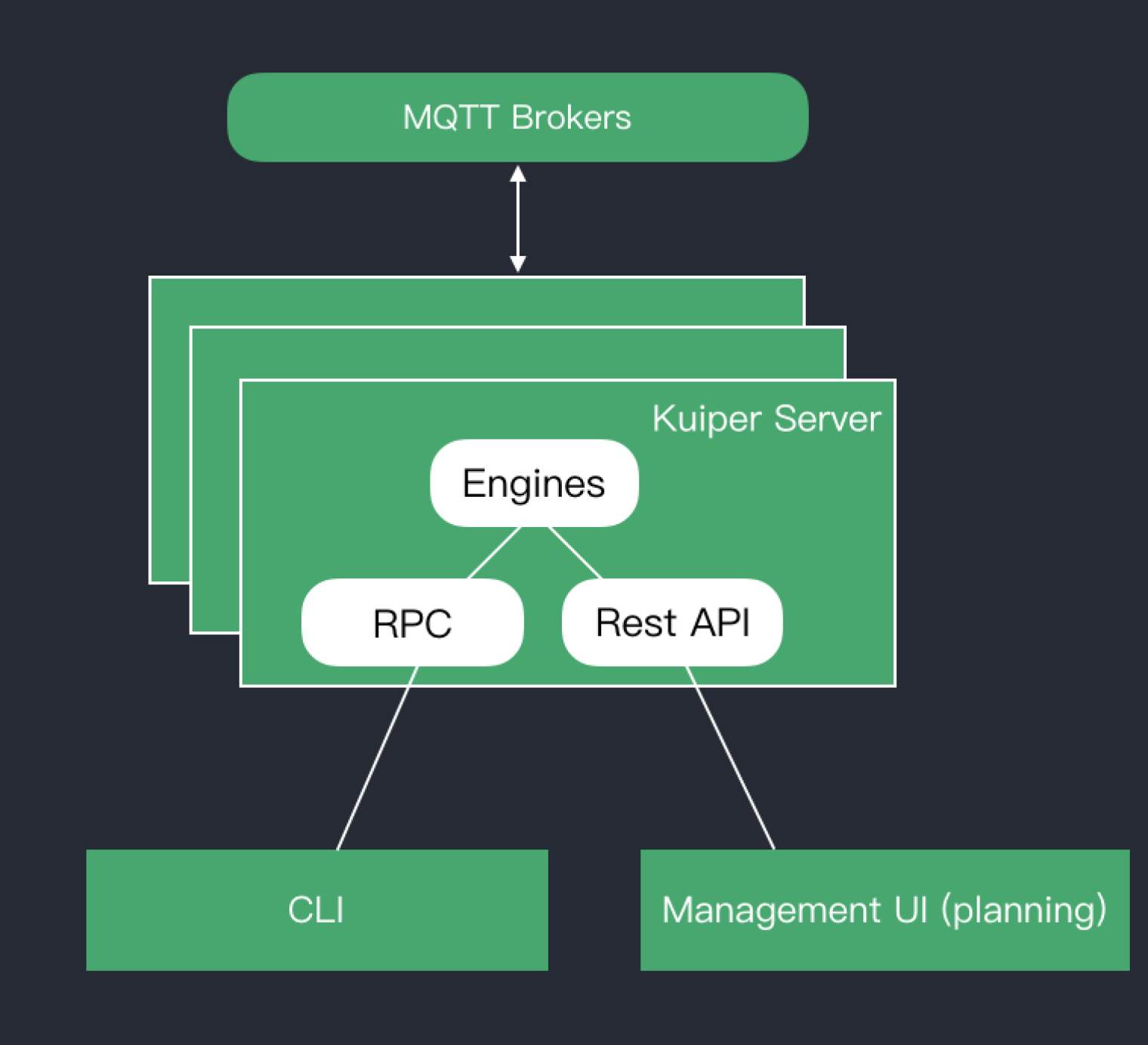
Kuiper 组件概述
如下图所示,Kuiper Server 包括了三部分,分别为
- Engines:这部分为核心的处理引擎,主要功能包括了 SQL 解析,SQL 运行时和流式数据处理框架等
- RPC 接口:RPC 接口主要用于跟客户端命令行工具的交互。包括流定义与管理,规则定义与管理,查询工具等
- Rest API 接口:Rest API 主要用于将来的管理接口,以及在计划中的管理界面的交互。包括流定义与管理,规则定义与管理,查询工具等
Kuiper 使用步骤概述
Kuiper 的使用过程与传统的流式工具类似,主要包括三步:流定义,规则定义,提交规则执行
流定义:这个步骤主要用于定义数据源流出的数据格式,类似于传统关系型数据库中定义表结构的过程。如下所示定义了一个名为 demo 的数据流
# bin/cli create stream demo '(temperature float, humidity bigint) WITH (FORMAT="JSON", DATASOURCE="demo")'规则定义:该步骤主要用于定义以下三部分内容
- 数据源(Source):这部分指定被处理的数据从何而来,在 SQL 的 FROM 语句中指定,就是在上一步中定义好的流的名称
- 数据业务处理(Process):这部分制定了如何处理数据,主要通过 SQL 语句的 SELECT、JOIN、GROUP、WINDOW(时间窗口),以及各种函数来实现
- 数据沉淀(Sink):这部分指定在数据处理完成后,将处理后的数据沉淀至相应的目标。目前支持将数据沉淀到 log 和 MQTT 服务器
{ "sql": "SELECT * from demo where temperature > 30", "actions": [{ "log": {} }] }如上所示,定义了一个规则,从名称为 demo 的流中,取出温度大于30的数据,并将满足条件的数据输出到日志文件中。规则可以保存在一个文本文件中,比如
myRule提交规则执行
# bin/cli create rule ruleDemo -f myRule完成规则后,通过创建规则命令就可以将其提交。满足条件的数据将被输出至日志文件。
... [{"humidity":17,"temperature":60}] [{"humidity":59,"temperature":68}] [{"humidity":67,"temperature":31}] [{"humidity":5,"temperature":45}] [{"humidity":34,"temperature":97}] [{"humidity":90,"temperature":73}] [{"humidity":72,"temperature":59}] [{"humidity":39,"temperature":72}] [{"humidity":76,"temperature":92}] [{"humidity":23,"temperature":40}] [{"humidity":74,"temperature":91}] [{"humidity":50,"temperature":76}] [{"humidity":77,"temperature":44}] ...
开始使用
读者可以通过按照在 Github 上的教程文档来完成 Kuiper 的首次体验。Kuiper 项目基于 Apache 2.0 开源协议,在使用过程中发现任何问题可以直接在项目中提交。
欢迎关注我们的开源项目 github.com/emqx/emqx ,详细文档请访问 官方文档。
