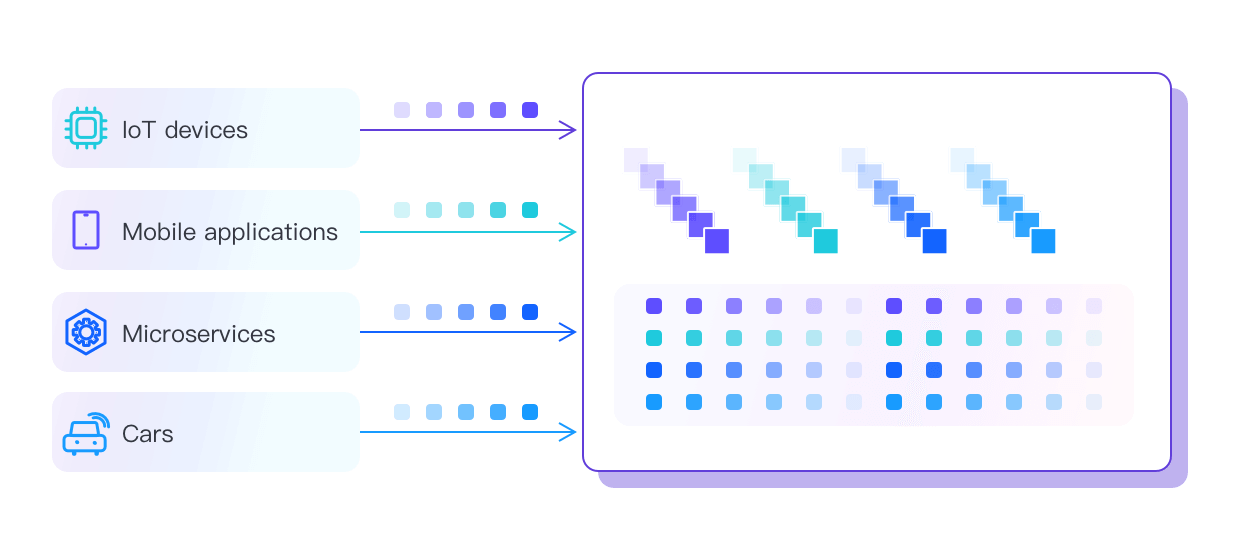
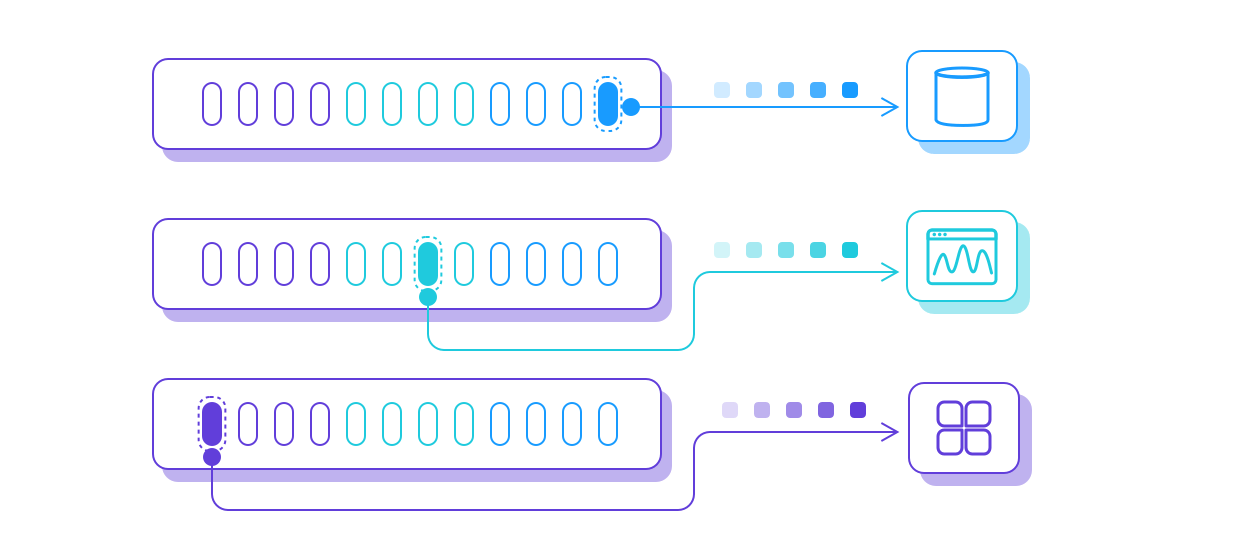
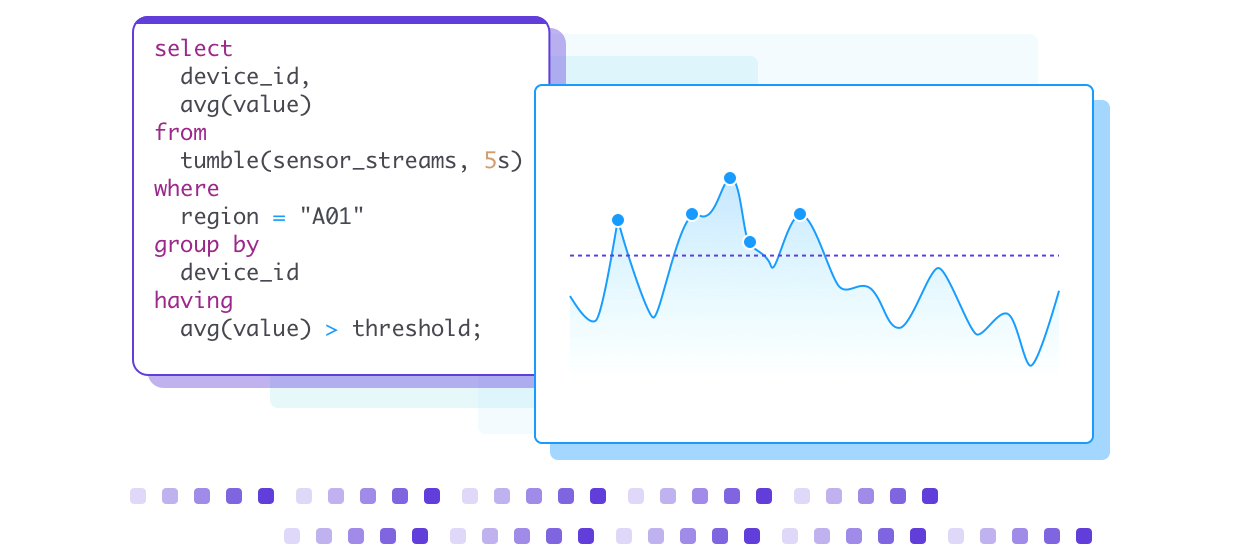

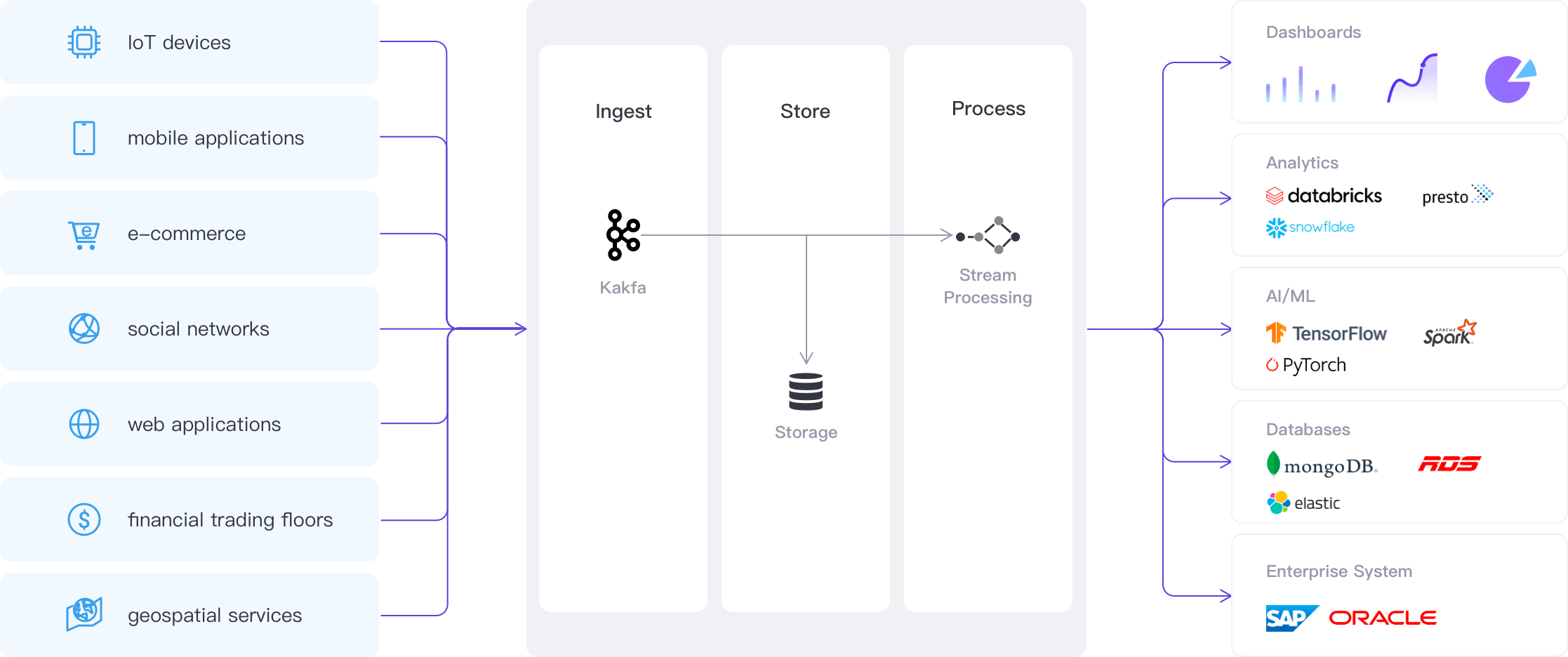


HStream Platform Serverless Beta Launched: A Comprehensive and Integrated Streaming Data Solution
HStream Platform Serverless is a one-stop streaming data platform service on the public cloud, enabling developers to handle streaming data with ease and efficiency.
Learn More →
