When database meets stream computing: the birth of the streaming database!
Database history review
As one of the cornerstones for modern software systems, databases have been studied for a long time. Although researches about databases have produced four Turing Award winners so far, it remains one of the liveliest and most innovative computer science topics. Ever since the 1970s, Edgar F. Codd proposed the relational model, relational databases based on the IBM SystemR prototype have proliferated and have been successful in many industrial applications. Even today, it remains the absolute mainstream.
With the rise and booming of the Internet in the 21st century, traditional relational databases began to struggle to meet the needs of fast-growing Internet businesses. Against this background, the NoSQL movement kicked off the database systems' era of being solely relational to various. This period saw the birth of many excellent database systems, including but not limited to:
- Document databases represented by MongoDB, CouchDB
- Wide-column databases represented by HBase, Cassandra
- A distributed, strongly consistent relational database represented by Google Spanner, including its open-source implementations CockroachDB, TiDB
- Analytical databases based on columnar storage represented by Apache Druid, ClickHouse
- Time series databases represented by InfluxDB, TimescaleDB
- Full-text indexing databases represented by Elasticsearch
- Graph databases represented by Neo4j
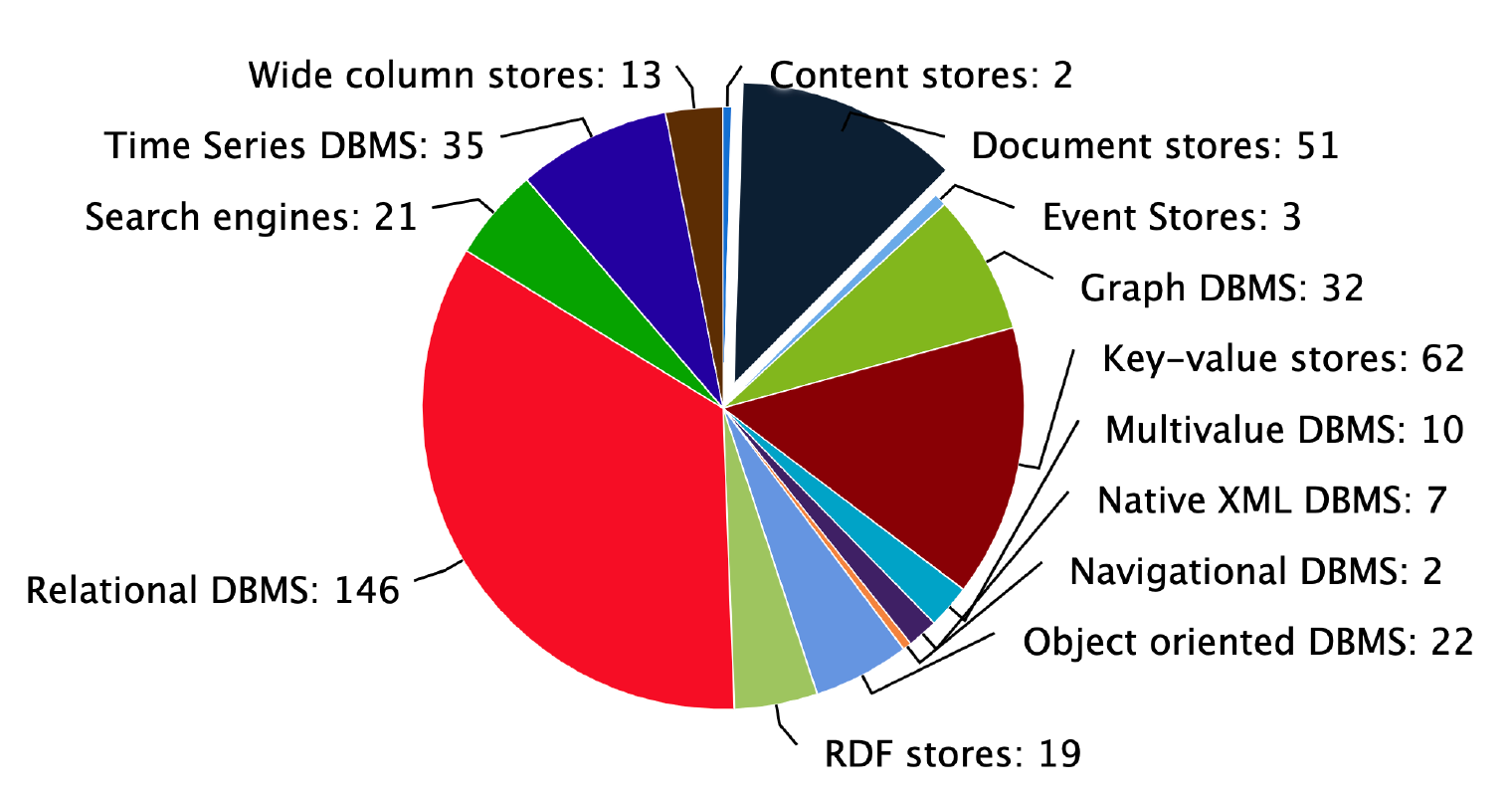
Figure 1: The number of different types of databases counted on db-engines
Figure source: https://db-engines.com/en/ranking_categories
What pushes developments and evolutions of database systems is that under the wave of global informatization, software systems continuously penetrate various industries. While at the same time, different industries, needs, and use cases keep putting forward new challenges to database systems.
So far, no database system can satisfy all the business needs of an entire industry or scenario - or even every need of a single company or organization. The reason is that because current real-world businesses' needs are increasingly complex and diverse. They often require different infrastructures for database systems in terms of data storage models, access models, the size and timeliness of the data stored, computational and analytical capabilities, and operational and deployment costs. Single database systems are generally developed based on particular storage and computational model and thus typically perform well only in their target scenario.
With the development of new industries, the opening of new business markets, and the future emerging needs of these new businesses, new database systems are bound to emerge. For example, the rise of the IoT industry and the AI industry in recent years has led directly to the creation of many new time series and graph databases.
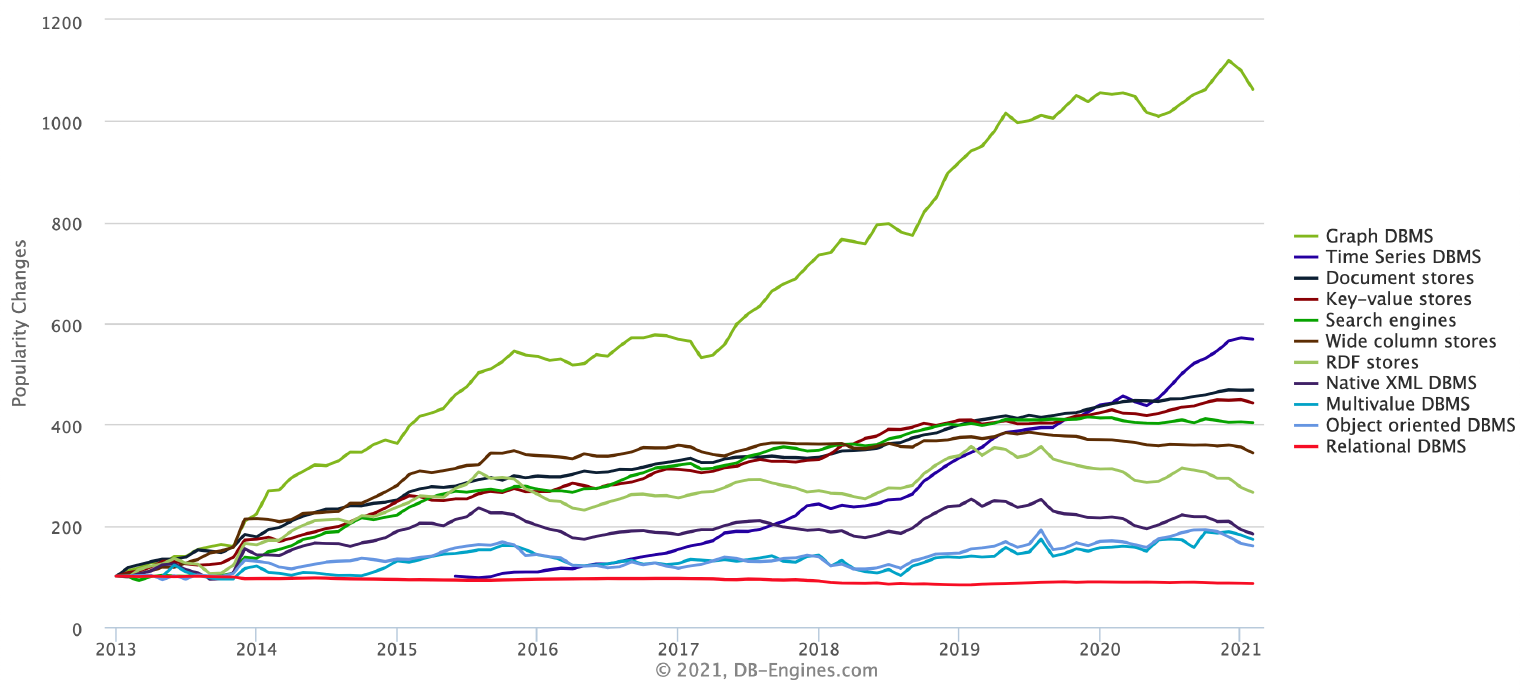
Figure 2: Change in prevalence of various databases since 2013
Figure source: https://db-engines.com/en/ranking_categories
New data storage and computing requirements are always the fundamental motivation for developments in database systems.
The rise of real-time stream computing
With the rapid development and expansion of computing and network technology, data is now generated in much richer ways from a much wider variety of sources than ever before, such as data from sensors, user activities on websites, data from mobile terminals and smart devices, real-time trading data from financial markets, data from various monitoring programs and so on. Many of these data are generated continuously in streams from multiple external data sources. And in most cases, we have no control over the order in which these streams arrive and the rate at which they are generated.
According to a report by a leading international analyst firm IDC1, Real-time stream data are occupying an increasingly large proportion of the overall data size.
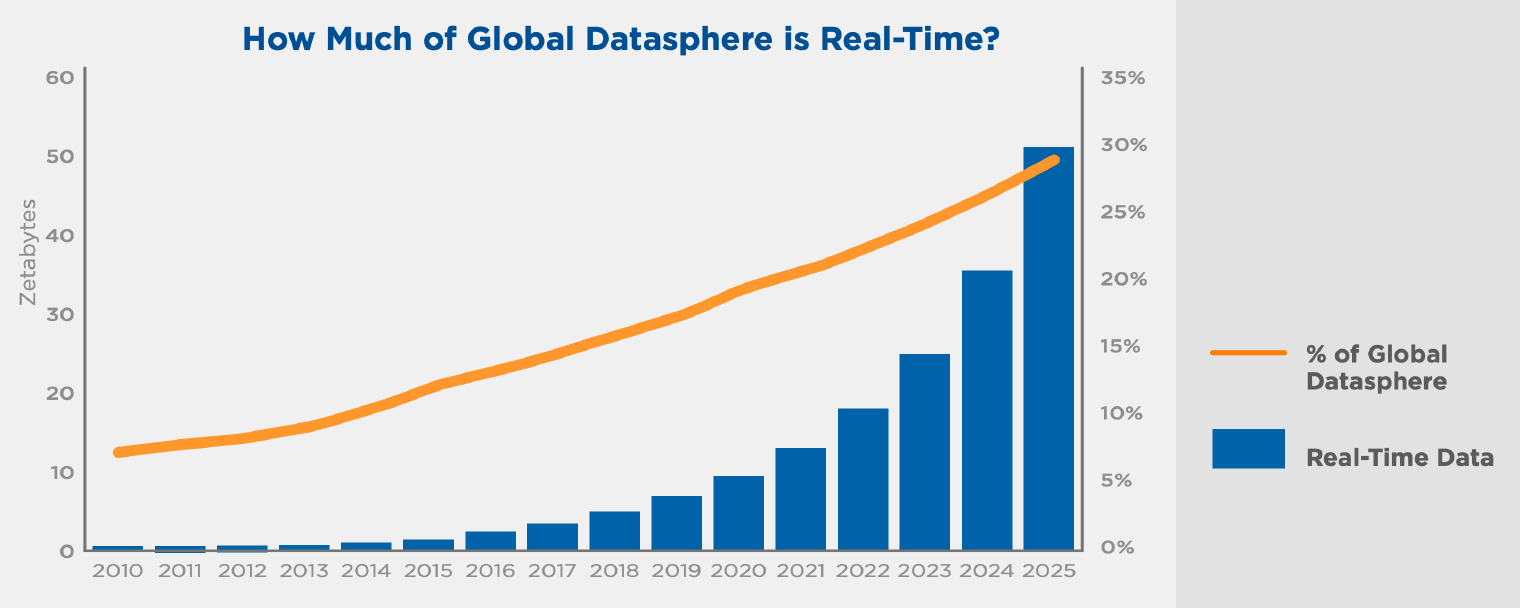
Figure 3: Trends in the growth of real-time data [1]
Traditional data processing systems generally calculate and analyze the intact static data already stored in database systems, file systems, and other storage systems, which are unsuitable for this type of continuously generated, infinite, and dynamic data stream. Moreover, traditional batch processing techniques usually have a relatively long time interval between data generation and data processing. However, in today's highly competitive and complex business environment, marketing opportunities are fleeting, risk prevention and control must be in a matter of seconds, and business decision-making must be quick and accurate. Therefore, data have to be processed in a shorter time, preferably even in real-time.
Against this backdrop, real-time stream processing techniques are beginning to replace batch processing in an increasing number of scenarios and take a central place in the modern data analysis technology stack. Unlike querying and analyzing static data, stream processing can model streams of data naturally and update computational results in real-time as new data come in. And this allows zero delays between 「data generation」 -> 「gaining data insights」-> 「taking action」, thus allowing companies to remain proactive and ahead of the curve in a highly competitive marketplace.
Today, stream processing systems are widely deployed and used by various enterprises and organizations. All major public cloud providers offer hosted services for streaming data storage and real-time processing, such as Amazon Kinesis, Google Dataflow, and Azure Stream Analytics. In the open-source community, we can also see the emergence of many software systems related to stream processing, such as Apache Storm, Apache Flink, Apache Beam, and many more. Moreover, over the last few years, more and more companies have built their own internal streaming data platforms enabling the whole organization to take advantage of the power of real-time computing, such as Uber's AthenaX, Netflix's Keystone platform, and Facebook's Turbine.
Challenges and opportunities for databases in the streaming era
Many enterprises and organizations have recognized the value of stream processing and are beginning to apply and deploy related systems. However, although a wide range of open source and commercial stream processing software is available, implementing a full stream processing technology stack remains challenging. In the process of actual implementation, it is found that current solutions generally suffer from complexity and difficulty in use, deployment, operation, and maintenance problems, high barriers to entry, miscellaneous components, non-uniform APIs, migration difficulties, etc. For example, basic stream processing solutions currently involve numerous distributed systems and components, including but not limited to.
- Real-time data collection and capture systems
- Real-time data storage systems
- Stream computing engines
- Downstream data and application systems
Another problem is that this brings a great challenge for development and maintenance and introduces more different components, leading to a less reliable system. Besides, these components and systems involved in the solutions are not always suitable and efficient, and the integration between them is not perfect. Therefore, it is often hard to meet the needs of the business. For example, to achieve exactly-once processing semantics and end-to-end consistency, the stream computing engine often relies on support from the stream storage system. This requirement is difficult to fulfill with general integration solutions.
An interesting phenomenon is that we usually use a specific database system to meet particular data storage and computation needs. However, when it comes to real-time data streams, such database systems are rarely available. The reason for this is that, on the one hand, a typical database system has a relatively high overhead of maintaining its storage and indexing structure, resulting in high write latency. And this does not meet the low latency storage requirements of large-scale real-time data streams.
A more important reason may be related to the 「stereotype」 of database systems: people think that database systems are all working under a request-response model, which is command-driven. In this model, the computation (command) is active while the data is passive. However, the model of stream processing is quite the opposite. It is data-driven; the data is active while the computation is passive, with a constant flow of data going through the computation and a continuous update of the results. It is not easy to associate stream processing with databases due to this kind of difference.
However, is this true for all database systems? The answer is undoubtedly no. There are already some of the databases that support a request-response command-driven model and also a data-driven one. For example, MongoDB's Change Streams feature, RethinkDB's ability to push data in real-time, and TimescaleDB's continuous aggregation feature.
Taking this one step further, we can expect using a professional database system to solve all our needs for data flow management, such as easy flow calculation via the familiar SQL language.
The birth of streaming database
In fact, we don't need some fragmented pieces of ETL tools, message middleware for temporary data storage, or isolated stream computing engines but a database system designed for streaming data, the streaming database for storing and processing real-time data streams.
The streaming database is not a new concept invented today but explored in a paper entitled Continuous queries over append-only database2, published in SIGMOD in 1992. Although it did not explicitly introduce the actual concept of streaming databases, our streaming database is in line with its main idea.
Besides, unlike other database systems that use static data sets (tables, documents, etc.) as the basic storage and processing unit, the streaming database uses streams as the basic object and real-time as their main feature. Streaming databases are a re-architecture and redesign of databases in the streaming era.
Summary
The development of database systems has entered a new phase. It's time to break away from those old concepts and create the future. In the background of increasing needs for computation and storage, we believe that the road ahead streaming database will be bright and promising.
Our next article will continue our in-depth discussion on the storage of streaming databases to explore what an efficient and reliable streaming database should look like.
Also, we welcome you to join us at EMQ to discover and create infinite possibilities for the streaming database.
