JMeter 扩展开发:BeanShell 数据模拟实现及性能探讨

在写 JMeter 脚本的时候经常需要模拟一些数据,通常的做法是采用”CSV Data Set Config”从 CSV 文件中读取数据。但是使用数据文件不够灵活,需要提前根据虚拟用户数准备相应数量的测试数据。比如,某应用的用户注册过程需要提供手机号码,如果采用 CSV 文件,测试 1000 虚拟用户就需要准备 1000 个手机号码。如果测试过程中要增加虚拟用户数目,则需要准备更多的测试数据。整个过程比较费时费力。
除了数据文件这种方法,对某些特殊的有规律的测试数据,我们也可以采用动态生成测试数据的方式,比如利用本文介绍的 BeanShell。
BeanShell 实现
我们仍然采用上述手机号码的需求。用户注册过程中需要提供手机号码,测试场景中除了用户注册之外,不会对手机号码产生实际操作行为(比如发送短信等),只需要符合数据库中表的定义即可(数据库中定义为 11 位 char 类型)。
实现过程需要考虑不同的虚拟用户在运行的时候不能使用相同的手机号码,另外还需要考虑同一个虚拟用户在多次循环执行的情况下也不能使用相同的号码,否则无法注册成功。为了实现上述需求,我们需要有一个标识虚拟用户的 ID ,以及在多次循环执行的情况下标识的当前循环次数的值。
标识虚拟用户可以通过 JMeter 的内置函数 __threadNum 来得到,而后者可以通过 JMeter 提供的计数器来实现,先来看一下我们的脚本的结构。“HTTP请求”需要使用手机号码发起一个测试请求,该手机号码是从一个名为 mobile 的 JMeter 变量中取得的,而该变量是通过“BeanShell 预处理程序”处理之后保存为 JMeter 的变量。
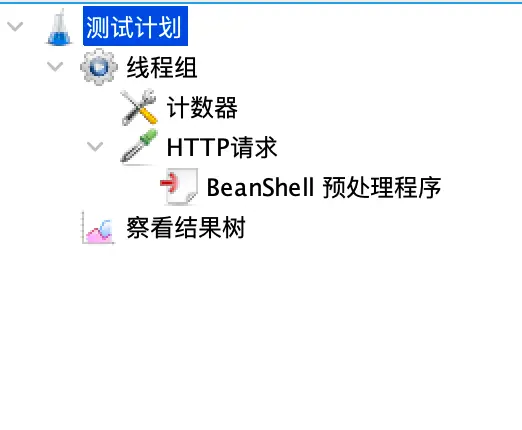
BeanShell 的实现,具体请看下面的代码。
import java.text.DecimalFormat;
String strThreadNum = "${__threadNum}"; //取得当前的虚拟用户ID
int thNum = Integer.parseInt(strThreadNum);
String str = "${iterNo}"; //取得该虚拟用户当前的循环次数, iterNo变量在计数器中定义
int i = Integer.parseInt(str);
int mobileNumLastFive = thNum * 10000 + i;
DecimalFormat df = new DecimalFormat( "0000000000" );
String fullNum = 4 + df.format(mobileNumLastFive); //格式化成4开头的11位手机号码
System.out.println(fullNum);
vars.put("mobile", fullNum); //将手机号码存入名为mobile的变量,该变量可以在“HTTP请求”中用到
计数器的设置如下图所示,其中的引用名称就是在 BeanShell 里引用的 iterNo 变量。

BeanShell 和 Java 扩展性能对比
为了实现 JMeter 不支持的功能,之前的博客中我们介绍了通过扩展 JMeter 函数相关的 Java 接口实现开发的方式,本文介绍的 BeanShell 脚本是另一种方式。接下来将比较两种不同实现方式对 JMeter 的性能影响。我们将通过实现一个简单的功能来进行比较,并对这两种不同的实现方式的使用场景提供推荐。
测试场景
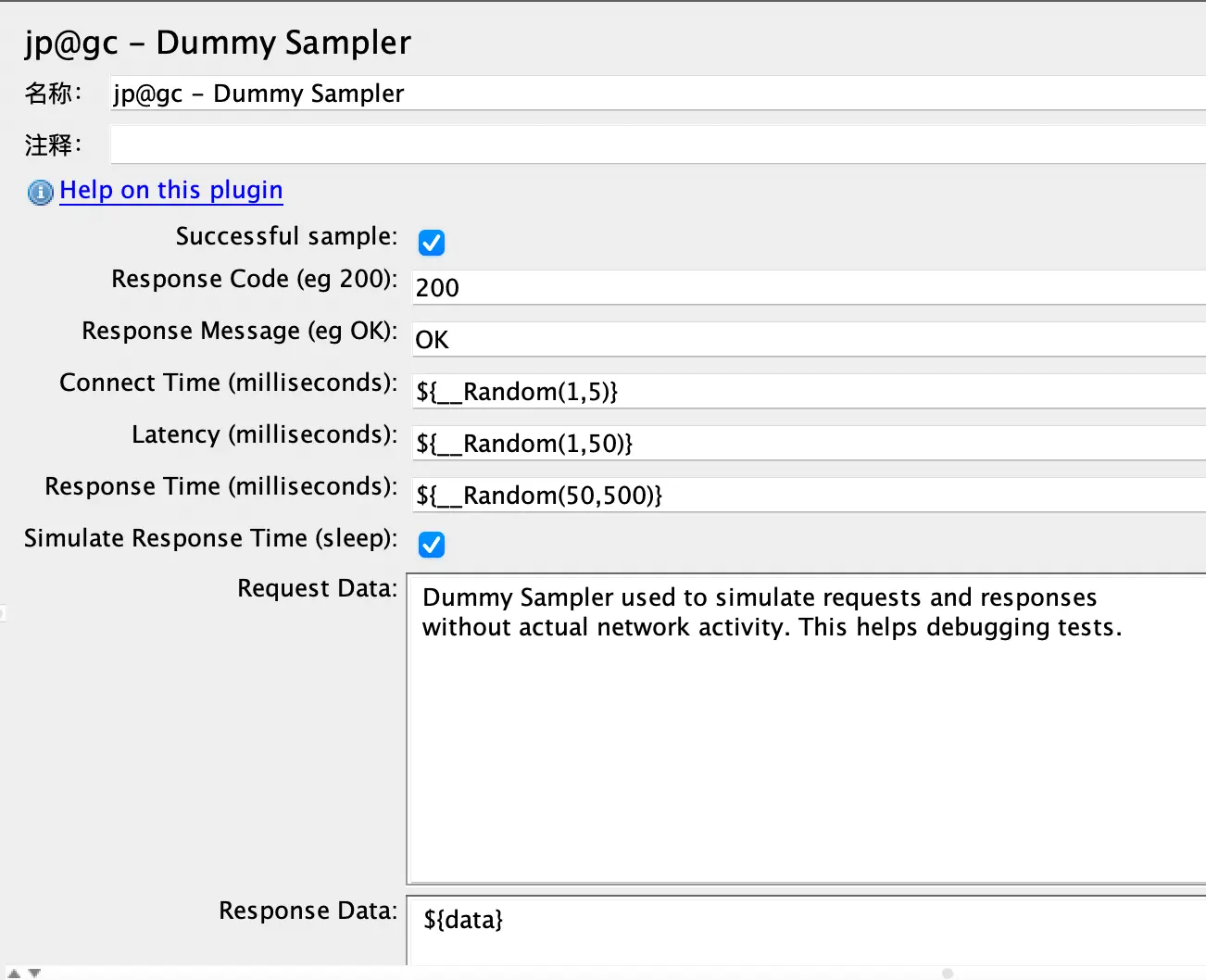
假设测试脚本需要产生一个长度为 1024 的随机字符串,字符串产生后将其赋值给一个名为”data”的变量,供后面的取样器来使用,在本文中使用的是“Dummy Sampler”(安装及介绍参见上一篇博客),利用它在自定义请求内容和响应内容上的优势。BeanShell 版的 JMeter 测试脚本结构如下:

BeanShell 方式
BeanShell 预处理程序中的代码如下,生成了随机字符串后将值赋值给变量“data”:
import java.security.SecureRandom;
char[] seeds = "abcdefghijklmnopqrstuvwxyz0123456789".toCharArray();
StringBuffer res = new StringBuffer();
SecureRandom random = new SecureRandom();
for (int i=0; i<1024; i++) {
res.append(seeds[random.nextInt(seeds.length - 1)]);
}
vars.put("data", res.toString());
res = null;
Dummy Sampler 中的“Response Data”输入框中传入变量“data”,如下图所示:
JMeter 自定义函数方式
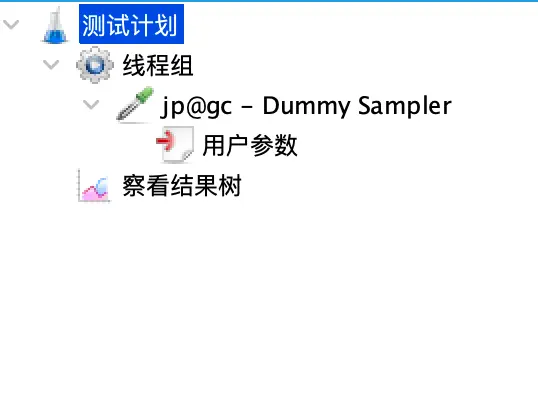
扩展 JMeter 函数的实现方式下,测试脚本的基本结构与 BeanShell 方式类似,可参见下图。不一样的地方是把“BeanShell 预处理程序”替换成了“用户参数”。
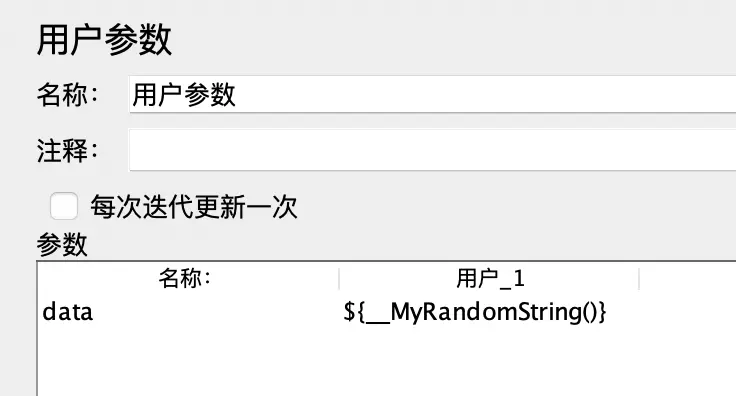
“用户参数”中加入一个变量,该变量的值是自定义扩展的一个函数的运行结果:${__MyRandomString()}。
该自定义函数 __MyRandomString 的实现代码如下所示,具体请参见上一篇博客来学习如何扩展自定义函数。
package com.emqx.xmeter.demo.functions;
import java.security.SecureRandom;
import java.util.Collection;
import java.util.LinkedList;
import java.util.List;
import org.apache.jmeter.engine.util.CompoundVariable;
import org.apache.jmeter.functions.AbstractFunction;
import org.apache.jmeter.functions.InvalidVariableException;
import org.apache.jmeter.samplers.SampleResult;
import org.apache.jmeter.samplers.Sampler;
public class MyRandomString extends AbstractFunction {
private static final List<String> desc = new LinkedList<String>();
private static final String KEY = "__MyRandomString";
private SecureRandom random = new SecureRandom();
private static char[] seeds = "abcdefghijklmnopqrstuvwxyz0123456789".toCharArray();
@Override
public List<String> getArgumentDesc() {
return desc;
}
@Override
public String execute(SampleResult previousResult, Sampler currentSampler) throws InvalidVariableException {
StringBuffer res = new StringBuffer();
for (int i=0; i<1024; i++) {
res.append(seeds[random.nextInt(seeds.length - 1)]);
}
return res.toString();
}
@Override
public void setParameters(Collection<CompoundVariable> parameters) throws InvalidVariableException {
}
@Override
public String getReferenceKey() {
return KEY;
}
}
测试配置
测试运行之前,将分别使用两种方式编辑的脚本的线程组的线程数都设置为 100,循环次数 100 次。
测试机器是申请的标准虚机: 1)2 核 CPU*2 GB 内存 2)20 GB 硬盘 3)操作系统 CentOS 7,64位 4)Java 版本是 Open JDK 8
JMeter 测试采用非UI方式运行。
测试结果
BeanShell 方式的脚本执行完测试约用了 1分18秒 左右,控制台打印出的测试结果如下。JMeter 进程 CPU 使用率为 137%,内存使用率为 14%。
summary + 2802 in 00:00:23 = 120.6/s Avg: 276 Min: 50 Max: 516 Err: 0 (0.00%) Active: 100 Started: 100 Finished: 0
summary + 4138 in 00:00:30 = 138.1/s Avg: 275 Min: 50 Max: 506 Err: 0 (0.00%) Active: 100 Started: 100 Finished: 0
summary = 6940 in 00:00:53 = 130.5/s Avg: 275 Min: 50 Max: 516 Err: 0 (0.00%)
summary + 3060 in 00:00:24 = 125.9/s Avg: 276 Min: 50 Max: 502 Err: 0 (0.00%) Active: 0 Started: 100 Finished: 100
summary = 10000 in 00:01:18 = 129.0/s Avg: 276 Min: 50 Max: 516 Err: 0 (0.00%)
Java 扩展 JMeter 函数的方式执行完测试约用了 32 秒,控制台打印出的测试结果如下。JMeter 进程CPU 使用率为 50%,内存使用率为 5%。
summary + 6544 in 00:00:19 = 348.5/s Avg: 273 Min: 50 Max: 501 Err: 0 (0.00%) Active: 100 Started: 100 Finished: 0
summary + 3456 in 00:00:14 = 252.6/s Avg: 277 Min: 50 Max: 501 Err: 0 (0.00%) Active: 0 Started: 100 Finished: 100
summary = 10000 in 00:00:32 = 308.1/s Avg: 274 Min: 50 Max: 501 Err: 0 (0.00%)
由测试结果可以看到 Java 扩展 JMeter 函数的方式下执行时间、CPU、内存占用率与 BeanShell 方式相比,占明显的优势。大家需要注意的是Avg、Min 和 Max 指的是“Dummy Sampler”的统计数据,两种使用方式下 Dummy Sampler 的执行时间是一致的,而吞吐量后者比前者多了将近 1 倍,原因就在于测试步骤中的请求数据生成的不同实现方式下,后者比前者快了很多。
使用建议
BeanShell 是 JMeter 内置的功能,但是由于它是脚本语言,动态加载执行的,因此效率不是很高,不太适用于频繁执行的场景,例如将 BeanShell 放在循环内部,不断被执行的场景。比较适合的应用场景是放在只执行一次、或者少数几次的地方,比如在循环外部读取配置文件内容等。
而 Java 扩展 JMeter 的实现方式运行效率比较高,适合于放在经常执行的测试步骤中。但是由于它不是 JMeter 内置的功能,扩展起来有一定的工作量,而且部署的时候也有额外的开销(分布式运行的时候需要将自定义的 JAR 拷贝至所有的机器上)。大家可以根据自己的使用场景来选择适合的方式。