eKuiper Newsletter 2022-07|v1.6.0:Flow 编排 + 更好用的 SQL,轻松表达业务逻辑

盛夏时节,eKuiper 本年度第二个大版本 v1.6.0 如约而至。面向 Flow 编排的图规则 API 的开发和内部试用打磨贯穿了整个夏季版本的开发过程,终于在 7 月完成。与此同时,我们也完成了多个 SQL 语法和函数的提升,期望 Flow 编排 和 SQL 双剑合璧能够帮助用户更容易地表达业务逻辑,覆盖更多样的使用场景,进一步减少定制开发的需求和成本。此外,我们也优化了外部系统连接的使用。例如 EdgeX 和 MQTT 连接中断时不再退出规则、SQL 和 TDengine Sink 支持批量写入等。
在之前的 Newsletter 中,我们已经陆续介绍过 v1.6.0 已开发完成的一些新功能,包括 protobuf 编解码的支持、离线缓存和重发等。本期 Newletter 将介绍其他新功能。完整的功能列表请查看1.6.0 Release.
面向 Flow 编排的图规则 API
在之前的版本中,eKuiper 的规则逻辑是通过 SQL + actions 的方式指定的。基于 SQL 语法的规则好处多多:
- SQL 语法应用广泛,对于有技术背景的用户来说,比较容易上手。
- SQL 语法简洁,在数据库领域已得到广泛验证,可以用很短的文本写出复杂的规则。
- SQL 是声明式的语言,执行引擎需要解析生成执行计划。这样,执行引擎可自行对实际运行的执行计划进行优化而无需用户做任何更改。
SQL 在处理数据变换为核心的规则时显得得心应手。然而在部分场景中,SQL 语法并不是很合适。
- 面向非技术人员的场景,SQL 难以上手。
- 对于某些场景,SQL 语法难以表达或者过于复杂。例如,对某个事件根据模式匹配做分流处理,温湿度传感器的数据,若温度大于某个值,则做一种流程,温度小于某个值则执行另一个流程。总体来说,Flow 可覆盖更多的场景。
- SQL 由于自身抽象程度高,难以实现 UI。
图规则 API 采用 JSON 格式,直接描述运行时执行的算子的有向无环图结构,可一对一映射成 UI 上的 Flow 编排。新的版本中,图规则 API 将作为 SQL 的补充提供。
值得注意的是,SQL 规则在新版本中仍然完整支持,用户可根据场景选用使用的 API。其中,SQL 更适合用户手写规则,而图 API 由于 JSON 结构冗长,较适合由 UI 生成。
使用方法
图规则 API 与 SQL 共用当前的规则 REST API endpoint,创建规则的时候通过指定 graph 属性来使用。graph 属性是有向无环图的 JSON 表述。它由 nodes 和 topo 组成,分别定义了图中的节点和它们的边。下面是一个由图形定义的最简单的规则。它定义了 3 个节点:demo,humidityFilter 和 mqttOut。这个图是线性的,即demo->humidityFilter->mqttOut。该规则将从 MQTT 的 demo 主题读取数据,通过湿度做过滤(humidityFilter)并将结果汇入 MQTT 的另一个主题(mqttOut)。
{
"id": "rule1",
"name": "Test Condition",
"graph": {
"nodes": {
"demo": {
"type": "source",
"nodeType": "mqtt",
"props": {
"datasource": "devices/+/messages"
}
},
"humidityFilter": {
"type": "operator",
"nodeType": "filter",
"props": {
"expr": "humidity > 30"
}
},
"mqttout": {
"type": "sink",
"nodeType": "mqtt",
"props": {
"server": "tcp://${mqtt_srv}:1883",
"topic": "devices/result"
}
}
},
"topo": {
"sources": ["demo"],
"edges": {
"demo": ["humidityFilter"],
"humidityFilter": ["mqttout"]
}
}
}
}
图的 JSON 中的每个节点至少有 3 个字段:
- type:节点的类型,可以是source、operator和sink。
- nodeType:节点的实现类型,定义了节点的业务逻辑,包括内置类型和由插件定义的扩展类型。
- props:节点的属性。它对每个 nodeType 都是不同的。
对于 source 和 sink,其 nodeType 与系统中内置的和通过插件扩展的类型完全对应。对于 operator 节点,我们提供了一系列对应 SQL 语法的内置节点,打到与 SQL 相同的表达能力。用户扩展的函数,可通过 funciton 节点或者 aggfunc 节点进行调用。完整的节点列表,请参考https://ekuiper.org/docs/zh/latest/guide/rules/graph_rule.html#内置-operator-节点类型 。
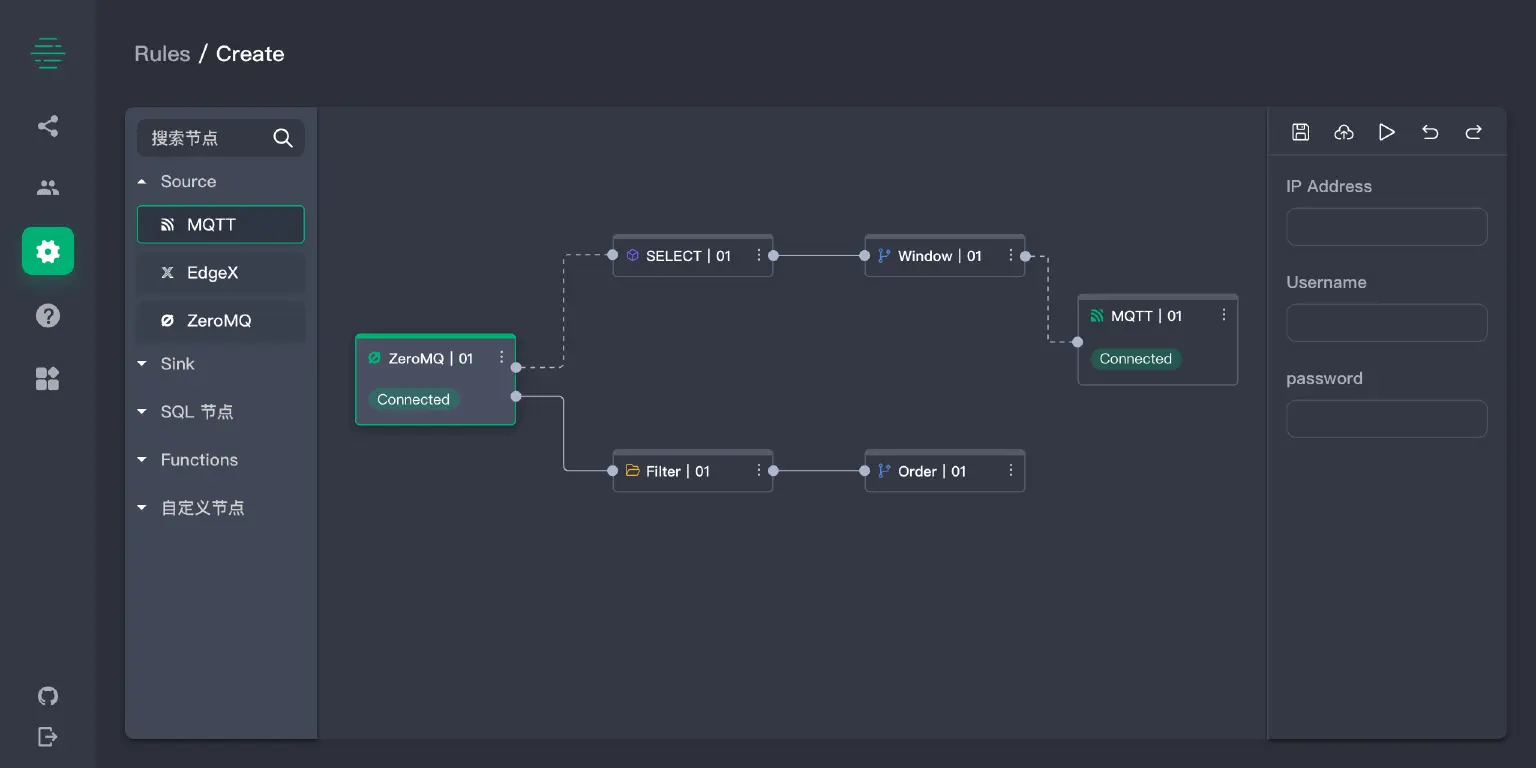
Flow Editor
在 eKuiper 核心版本中仅提供后台的图规则 API,厂商和用户可基于此实现拖拽的图形界面。我们也将在近期推出 Flow 编排 实现,方便用户使用。
参考实现的图形界面如下所示。图形界面中可在左侧画板中列出可用的内置和扩展节点,允许节点拖拽到画布上并连接成图、设置属性等。画板上的数据流图可方便地表示为 JSON,通过图规则 API 进行创建。
SQL 更新,编写规则更轻松
新版本中添加了几个 SQL 语法相关的更新:提供了 LAG 函数用于获取数据流中之前的值;提供了 BETWEEN 和 LIKE 语法;修改了时间窗口使其对齐到自然时间。
LAG 函数助力有状态分析
LAG 函数可查看数据流里之前的数据并与当前的数据进行计算。它对于计算一个变量的增长率,检测一个变量何时越过阈值,或一个条件何时开始或停止为真等等依赖缓存状态的计算都非常有用。之前版本中,有状态计算依赖于窗口或者用户自行扩展的插件,复杂度较高。LAG 函数可以大大降低有状态分析的门槛。
其使用语法为 lag(expr, offset, default value),返回表达式前一个值在偏移 offset 处的结果,如果没有找到,则返回默认值,如果没有指定默认值则返回 nil。如果除 expression 外其余参数均未指定,偏移量默认为 1,默认值为 nil。在下例中,我们计算了温度值的变化率。
SELECT lag(temperature) as last, temperature, lag(temperature)/temperature as rate FROM demo
更多过滤方式
新版本中添加了 BETWEEN 和 LIKE 语法。其中,BETWEEN 用于数字类型数据的过滤,选出在一个范围内的数据。LIKE 用于字符串的过滤,选出满足某个模式的字符串。在下例中,我们选出了温度在 15 到 25 之间,同时 deviceName 以 device 开头的数据。
SELECT * FROM demo WHERE temperature BETWEEN 15 AND 25 AND deviceName LIKE "device%"
自然时间窗口
之前 eKuiper 时间窗口的开始时间是以实际窗口开始运行时间为准的。但是在实际场景中,时间的聚合通常都是基于自然时间。例如,1 个小时的时间窗口,期望的结果是每个自然小时的聚合。大部分的流式处理引擎也会将时间窗口对齐到自然时间中。因此,在本版本中,时间窗口的聚合也对齐到系统时区的自然时间。
更高效和稳定的连接
eKuiper 通过 source 和 sink 与外部系统进行连接。本版本中着力提高连接的稳定行和效率,主要改进了现有的 source 和 sink 的功能。
数据库批量写入
在 SQL sink 和 TDengine Sink 中,添加了属性 tableDataField,可写入内嵌的数据(单行或多行)。同时,二者在接收到数组数据(多行数据)时,将一次性批量写入所有的数据。
稳定 EdgeX 连接
改进了 EdgeX 的连接逻辑,当消息总线连接中断时不会立即退出规则也不会打印大量的 log 造成风暴。消息总线恢复后,可自动重连。总之,连接 EdgeX 的规则在创建后运行更加稳定,不会因为可恢复的错误而退出。