EMQX Performance Tuning: Linux Conntrack and MQTT Connections

In previous blogs, we introduced the impact of file descriptors and TCP's SYN and Accept queues on TCP connections. Today, we will explore another factor that could limit the maximum number of connections.
Taking an EMQX node with a hardware configuration of 8 cores and 4GB as an example, after establishing approximately 65,536 MQTT connections, we may find that even if the number of connections has not reached the file descriptor limit, and the TCP's SYN and Accept queues have not overflowed, we still can’t establish more MQTT connections. Moreover, the following logs then appear in the operating system:
nf_conntrack: table full, dropping packet
This means the current OS has dropped a new connection request because the connection tracking table is full. In this blog, we will introduce the reasons for this phenomenon and how to resolve this issue by adjusting kernel parameters.
What is Connection Tracking?
Connection Tracking (conntrack) is a core function of the Linux kernel network stack, provided by the nf_conntrack module. Once the nf_conntrack module is loaded, the connection tracking function starts working. It determines whether each passing packet belongs to an existing connection. If it does not belong to any existing connection, the nf_conntrack module will create a new conntrack entry. If the connection already exists, it updates the status, expiration time, and other information of the corresponding conntrack entry.
We can use the conntrack command to view the current tracked conntrack entries:
# Install conntrack
$ apt-get install conntrack
# List conntrack
$ conntrack -L
In some operating systems, such as CentOS, you can also use the following command to view:
$ cat /proc/net/nf_conntrack
The following is a typical conntrack entry, which records the source IP, destination IP, and other information of a TCP connection in the ESTABLISHED state with bidirectional data transmission.
tcp 6 295 ESTABLISHED src=192.168.0.175 dst=100.125.61.10 sport=51484 dport=10180 \ src=100.125.61.10 dst=192.168.0.175 sport=10180 dport=51484 mark=0 zone=0 use=2
In addition to TCP, a connection-oriented protocol, the nf_conntrack module also tracks packets of connectionless protocols such as UDP and ICMP. Therefore, it would be more appropriate to say that it tracks data flow rather than connections.
Common Applications of Connection Tracking
Connection tracking is the basis for many network applications, the most common use case is NAT (Network Address Translation).
For machines in an internal network to access external services, we usually need to create an SNAT rule, replacing the source IP of the outgoing packet from the original internal IP to the public IP of the NAT gateway.
When the external service returns a response packet, the destination IP in the response packet will be the IP of the NAT gateway. To correctly return the response packet to the machine in the internal network, the NAT gateway needs to modify the destination IP in the packet to the corresponding internal IP.
But we don't need to explicitly create a DNAT rule corresponding to the SNAT rule, because the nf_conntrack module will record the NAT’s connection status, and the reverse transformation of the NAT address will be automatically completed according to the corresponding conntrack entry.
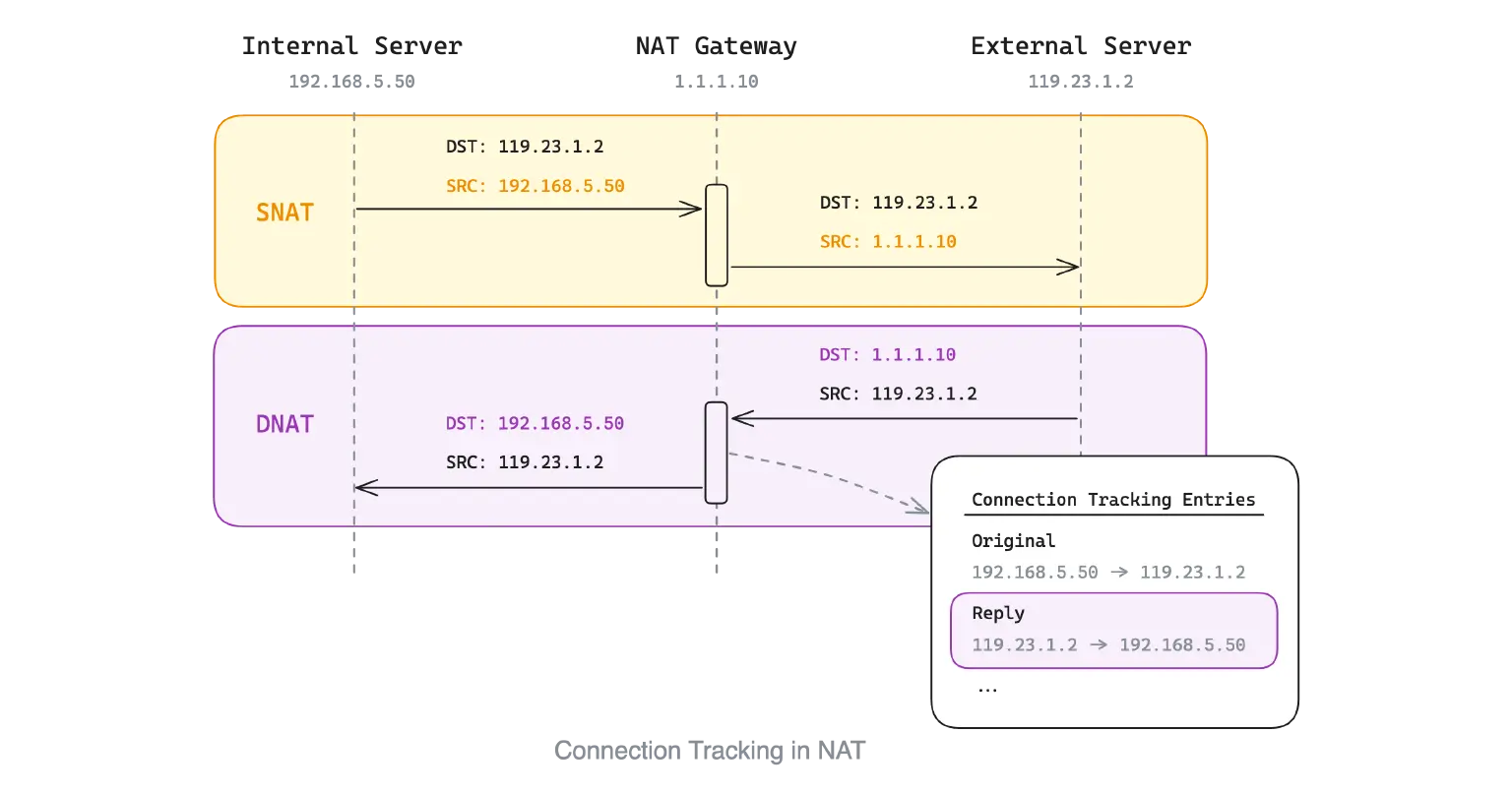
Network services and applications that provide services using NAT, such as Docker's Bridge network, Kubernetes Service, and the four-layer load balancing LVS, all depend on the connection tracking mechanism.
Another common application of connection tracking is stateful firewalls. Before this, stateless firewalls only independently review incoming and outgoing packets without considering whether the packets are part of a session or connection. Therefore, they can only set simple rules, such as dropping or allowing SYN packets on port 80.
In contrast, stateful firewalls can review packets based on the status information of connection tracking. They consider not only the content of the packets but also the context of the packets in the entire connection.
For example, when we write a rule that "allows this computer to connect to 122.112.202.251", there is no need to explicitly allow response traffic from 122.112.202.251 through other policies. In a stateless firewall, we have to add, a somewhat risky rule that "allows all traffic from 122.112.202.251".
The commonly used firewall management tool in Linux, iptables, as well as ufw and firewalld built on top of iptables, all rely on the underlying connection tracking mechanism.
Limitations and Optimizations of Connection Tracking
The Linux kernel uses a hash table to store connection tracking entries. The hash table consists of buckets, each bucket contains a doubly linked list, and each list can store several connection tracking entries. A connection corresponds to a connection tracking entry, but its connection tracking entry will be added to the hash table twice, representing the original direction and reply direction of the data flow1.
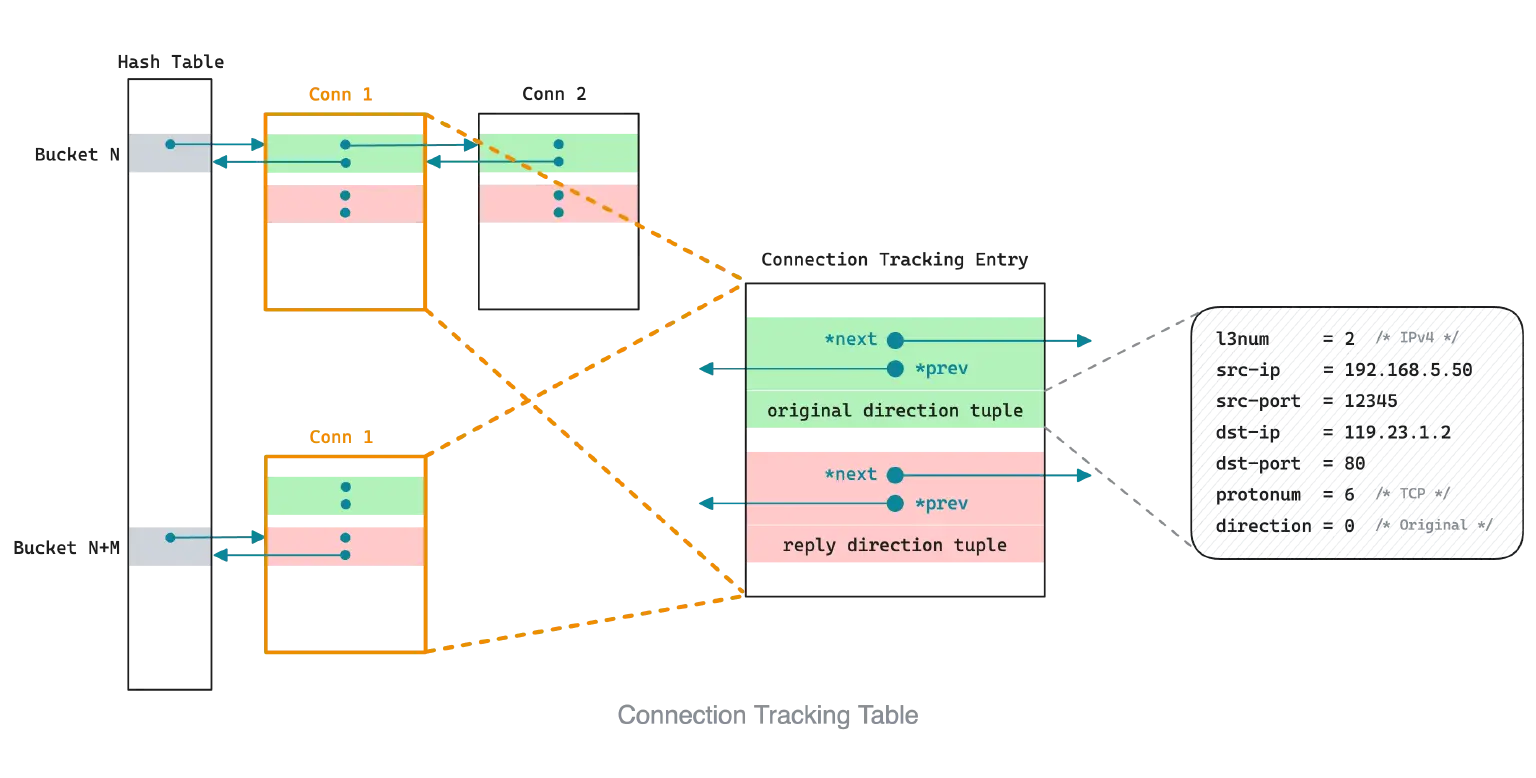
Each conntrack entry will occupy a certain amount of memory, so the operating system will not store conntrack entries indefinitely.
The default maximum number of conntrack entries may not meet our connection needs. We can adjust the maximum number of connection tracking entries that can be allocated using the kernel parameter net.netfilter.nf_conntrack_max.
Correspondingly, we also need to use net.netfilter.nf_conntrack_buckets to adjust the size of the hash table, that is the maximum number of buckets. nf_conntrack_max and nf_conntrack_buckets determine the average length of the linked list in the bucket.
Every time a packet is received, the Linux kernel will perform the following operations:
- Calculate the hash value according to the tuple of connection (source IP, source port, protocol number, etc.) in the packet to determine the position of a bucket.
- Traverse the bucket to find whether there is a matching conntrack entry. If not, create a new entry. If so, update the original entry information.
The hash calculation time in the first step is relatively fixed and very short, but in the second step, the larger the bucket size, the longer the traversal time. For conntrack performance considerations, the smaller the bucket size, the better. We usually follow the Linux kernel's recommendation to set the bucket size to 1, and it should not exceed 8 at most.
Starting from version 5.15 of the Linux kernel, nf_conntrack_max is set to the same value as nf_conntrack_buckets by default. That is, when the connection tracking table is full, the average length of the linked list in the bucket will be 2.
In earlier versions of the kernel, nf_conntrack_max was set to 4 times the value of nf_conntrack_buckets by default, which means that when the connection tracking table is full, the average length of the linked list in the bucket will be 8.
The calculation rule for the default value of nf_conntrack_buckets has changed several times with the iteration of the kernel version. In newer kernel versions, such as 5.15, when the system memory is greater than 4GB, nf_conntrack_buckets defaults to 262,144; when system memory is less than or equal to 4GB but greater than 1GB, nf_conntrack_buckets defaults to 65,536; when the system memory is less than 1GB, the default value of nf_conntrack_buckets will depend on the actual memory size2.
For simplicity, we can use the following command to view the currently effective value directly:
$ cat /proc/sys/net/netfilter/nf_conntrack_buckets
$ cat /proc/sys/net/netfilter/nf_conntrack_max
When the connection tracking table is full, the Linux kernel discards newly arrived packets because it cannot allocate conntrack entries for new connections, such as SYN handshake packets for TCP connections. This leads to the connection failure phenomenon we observe.
In addition to checking the system log, we can also confirm in the following ways:
- Check whether the number of currently conntrack entries has reached the maximum limit:
# Command 1 $ sudo sysctl net.netfilter.nf_conntrack_count # Command 2 $ sudo conntrack -C - Use the
conntrackcommand to check if the drop count has increased:$ sudo conntrack -S
After confirming the cause, we usually have two solutions:
Solution 1 - Disable nf_conntrack module
As mentioned earlier, conntrack is mainly used for NAT, stateful firewalls, and other applications. Therefore, if we can confirm that no application depends on conntrack, we can directly disable the connection tracking mechanism, which is a permanent solution.
For example, we deployed an EMQX cluster in a private network environment using cloud servers, and public network traffic flows in from the LB, and we used the security group policy provided by the cloud vendor to replace the firewall.
Because EMQX is not directly exposed to the public network and does not need NAT forwarding and firewall, we can use the following command to directly unload the nf_conntrack module in the machine where EMQX is located:
$ modprobe -r nf_conntrack
Solution 2 - Increase the conntrack table size
Suppose applications like Docker are relying on conntrack, and we can't disable it directly. In that case, we need to adjust the size of the connection tracking table based on the expected number of connections. We can use the sysctl command for temporary modifications:
$ sysctl -w net.netfilter.nf_conntrack_max=1048576
$ sysctl -w net.netfilter.nf_conntrack_buckets=1048576
If the kernel version is lower, we may be unable to modify the nf_conntrack_bucket parameter directly. In that case, we can use the following command to modify it:
$ echo 262144 > /sys/module/nf_conntrack/parameters/hashsize
If we want to make the change permanent, we can add the following two configuration lines at the end of the /etc/sysctl.conf file:
net.netfilter.nf_conntrack_max = 1048576
net.netfilter.nf_conntrack_buckets = 1048576
Don't worry that the above settings will cause conntrack entries to use too much memory. Execute the following command:
$ cat /proc/slabinfo | head -n2; cat /proc/slabinfo | grep nf_conntrack
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
nf_conntrack 144 144 320 12 1 : tunables 0 0 0 : slabdata 12 12 0
Through the column <objsize>, we can know that each conntrack entry occupies 320 bytes. If we ignore memory fragmentation, the memory occupied by 1,048,576 conntrack entries is approximately 320 MB, which is acceptable for modern servers 3.
However, since the setting of sysctl parameters occurs before the nf_conntrack module is loaded during the Linux boot process, only write the configuration of parameters like nf_conntrack_max into /etc/sysctl.conf cannot make them take effect. This is a known issue with sysctl4.
To solve this problem, we can create a 50-nf_conntrack.rules file in /etc/udev/rules.d and then add the following udev rules, indicating that the corresponding parameter settings are only executed when the nf_conntrack module is loaded:
ACTION=="add", SUBSYSTEM=="module", KERNEL=="nf_conntrack", \
RUN+="/usr/lib/systemd/systemd-sysctl --prefix=/net/netfilter"
After completing the above modifications, we can restart the system to verify whether the changes have taken effect.
Timeout thresholds of Connection Tracking Entries
In addition to nf_conntrack_max and nf_conntrack_buckets, by running the following command, we will also see many other kernel parameters related to nf_conntrack:
$ sysctl -a | grep nf_conntrack_tcp_timeout
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 432000
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
Those who are familiar with TCP will easily recognize that CLOSE-WAIT, FIN-WAIT, and others are all TCP connection states. These timeout parameters indicate the maximum time that tracking entries under different TCP connection states can be maintained if no new packets arrive.
In theory, we can shorten these timeout thresholds to speed up the recycling of conntrack entries and improve the utilization of the conntrack table. For example, the default value of nf_conntrack_tcp_timeout_established is 432,000 seconds, which means that an established TCP connection can last for 5 days without any packet interaction while the kernel still retains its tracking entries.
Generally, we can reduce it to 6 hours.
$ sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established = 21600
If we want to make changes permanent, we can write the configuration into /etc/sysctl.conf:
$ echo 'net.netfilter.nf_conntrack_tcp_timeout_established=21600' >> /etc/sysctl.conf
However, it's important to note that the default values for most other timeout thresholds are consistent with the TCP protocol specifications. The determination of these default values usually involves complex considerations. Therefore, unless you are certain of the potential impact of the changes, it is generally not recommended to modify them.
Conclusion
The connection tracking mechanism in Linux is the foundation of many network applications, but it may affect our connection establishment, so it's necessary to adjust the maximum size of the connection tracking table promptly, while also avoiding the negative impact of oversized buckets on network performance.
Shortening the timeout thresholds of connection tracking entries can theoretically improve the utilization of the connection tracking table, but hasty modifications may bring unexpected side effects.
If you can confirm that no application depends on the connection tracking mechanism, the simplest method is disabling it directly.
This concludes the tuning guide for connection tracking in Linux. In subsequent blogs, we will continue to bring more optimization guides for kernel parameters in the Linux system that affect the performance of EMQX.