Introducing ReplayQ, EMQX's Buffer Layer for Resilient IoT Data Integrations
EMQX is the most scalable MQTT broker for IoT, IIoT, and connected vehicles. It is also highly extendable to integrate with various databases and streaming platforms. EMQX Enterprise’s Rule-Engine provides a rich set of data integrations out of the box. To name a few: PostgreSQL, MySQL, InfluxDB, and Kafka.
You can find the complete list in EMQX Enterprise documents.
Since version 4.3, EMQX Enterprise supports a local send buffer for Kafka integration.
This buffer layer, named replayq, makes EMQX data integrations more resilient to network disturbances and service downtime.
In this post, we will first explain why this buffer is needed, then we will take the Kafka integration as an example, to introduce the high-level design, then drill down for more details to understand better how replayq works.
Why Do We Need a Buffer?
In each EMQX node, Kafka producer is a pool of workers, one for each Kafka partition. As illustrated below, for a Kafka topic having M partitions, there will be a pool of M workers running in each EMQX node.
As you may already know, EMQX is written in the Erlang programming language. If we use the Erlang jargon, the ‘worker’ in this context is an Erlang ‘process’. Unlike Linux processes, Erlang processes are extremely lightweight, operate in memory isolation, and are scheduled by Erlang’s Virtual Machine (VM).
In EMQX, there is one dedicated process for each MQTT client, and Kafka producers are no exceptions, they are processes too.
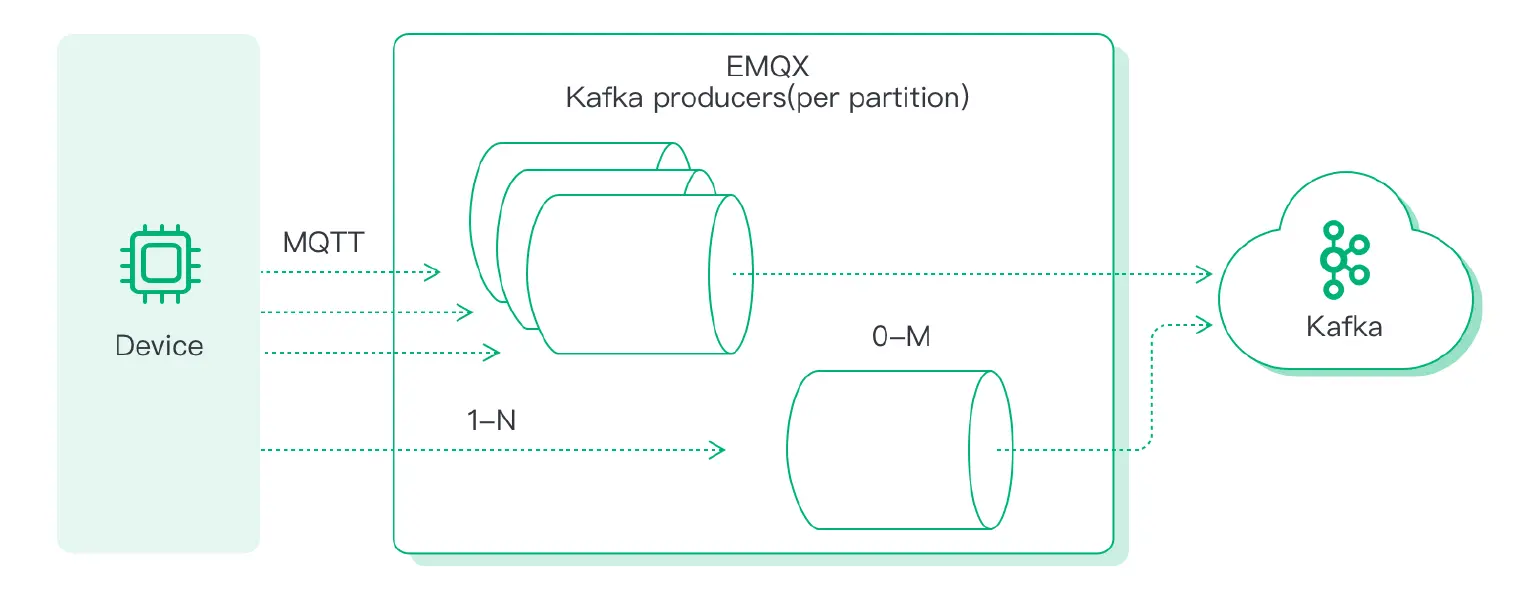
In the ideal world, this data flow should be smooth, all the network/software components have enough capacity to handle the data stream with little to no pushbacks toward the client. However, in a lot of cases, there can be congestions, and even connection losses. Given the limited computation & networking environment, there isn’t really a good solution to fix congestions and network disturbances altogether, instead, we try to mitigate the impact of them.
A slight congestion may only result in a bit more push-backs towards the clients. For example, they may in such cases experience higher latency receiving PUBACKs from the broker for QoS 1 messages.
In some cases, things may get a bit more complicated than just a latency increase, such as:
- Network disturbances from EMQX to Kafka
- Kafka is (temporarily) down (Yes, Kafka is highly available, but there are always exceptions)
- A burst increase of MQTT traffic higher than the planned network or CPU capacity on the Kafka side.
This is when MQTT clients may start experiencing timeouts.
And this is when we’d start to wish that EMQX could smooth out the spikes and mitigate the (temporary) errors — the buffer named replayq was introduced for this exact purpose.
We may consider the producer workers as queues. Having the 'queue' concept in mind will help to understand the rest of this document.
What is ReplayQ
replayq is a queue library originally used in EMQX Kafka, and later made into a generic solution. It offers a generic queueing mechanism for queueing messages in RAM or on disk depending on how it is configured.
The name ‘replay’ comes from its ability to buffer the messages in disk, and potentially replay old messages.
Different Buffering Mode
For the queues to buffer message, EMQX provided two different buffering modes
- Memory only
- Disk Mode
The “Memory only” mode is used when the data bridge is not configured with a replayq data directory. The buffered messages are volatile in this mode, if the node restarts, all the buffered messages are lost. Compared to no buffer at all, the advantage of having an explicit “Memory only” buffer is its overload protection (which will be discussed later in this post).
The Disk Mode
To make it easier to understand how disk mode works, let’s zoom in a little, only looking at one specific buffer queue.
Variants
There are three different variants of the dis mode
- normal (
offload=false)- Every enqueue operation causes disk write. This can be iops-intensive if the enqueue rate is high.
- offload (
offload=true)- Only write to disk after a certain amount of bytes accumulated in RAM. This means the messages hold in RAM are volatile, but the messages stored on disk will survive reboots.
- volatile-offload (
offload={true, volatile})- The same as offload mode, but all queue elements are volatile, including the elements stored on disk.
Segmented
In “Disk” mode, messages are stored in files, to store messages on disk, there are two extreme designs
- One file for each message. This is practical when there are only a few messages to buffer, because there are only so many inodes a file system can allocate, at some point, it will just be too costly even just to enumerate all the files on disk.
- All messages in one file. This is practical when there is only a limited number of bytes to buffer. Almost all file systems have a size limit for a single file, some are arguably large enough for most of the use cases, but the drawback is the overhead of scan or seek (to skip already consumed data).
This is why we choose to strike a balance in between: The buffer consists of a series of files called “segments”.
Segmenting files can improve the performance and manageability of the data. By dividing into smaller segments, it is easier to access specific parts of the stream and search for specific information. Additionally, segmenting allows for easier management of the data, such as archiving or deleting old segments to free up space.
As shown in the diagram below. New messages entering the queue will be appended to the rear (last) segment file.
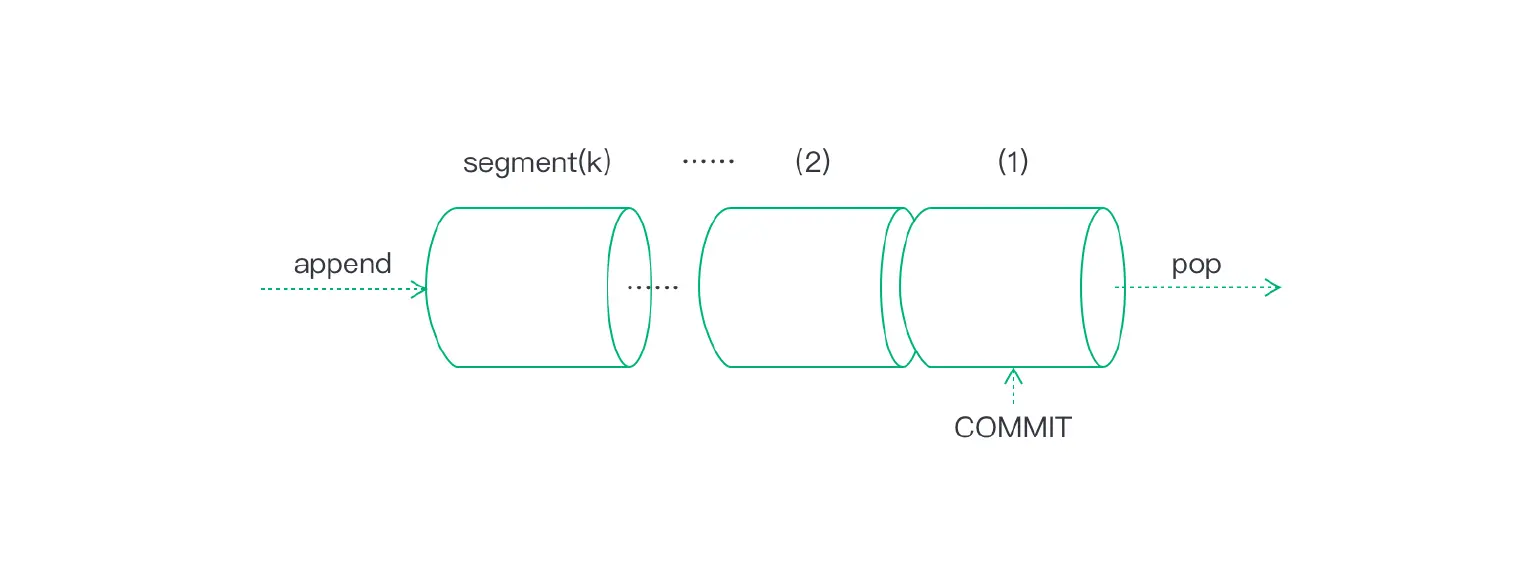
When the segment size grows beyond the configurable “segment bytes” limit, a new segment file will be created.
When popping out, the full head (oldest) segment is loaded into memory, which then works like a regular in-memory queue. The difference, compared to an in-memory queue, is that we need to record a cursor (the COMMIT) on disk after the popped elements are successfully processed.
COMMIT
In memory mode, the queue is mutable, popping out items from the head of the queue will shrink the size of the queue (i.e. leaving behind the tail part). However, when the queue is a file on disk, mutating the file would become overwhelmingly expensive to perform disk IO.
So we need a way to record a cursor (a logical position) to help us quickly locate the place where it was left off after a restart in order to avoid reprocessing old messages. This is why the COMMIT marker file was introduced.
The commit file essentially records two pieces of information: 1) the segment number; 2) the queue element ID (a sequence number within the segment).
For instance, if the COMMIT marker file recorded segno = 1, id = 10, it means messages with ID from 1 up to 10 are all consumed, hence after a restart, it should start reading messages from segment-1 but skip over the first 10 messages.
Corruption
Due to various reasons, data written to disk might end up corrupted, which is more likely to happen in scenarios like power outage, network disturbances for network attached block devices, or operating system itself runs out of RAM, etc.
Usually, corruptions happen at the end of a segment file (e.g. exception before the operating system had the chance to sync the changes from levels of caches down to the hard drive).
In order to detect corruption, queue-elements are written to disk together with a 4-byte magic number, and a checksum (CRC32). When re-opening the replayq segment files (e.g. after restart), a full scan is performed to detect corruptions.
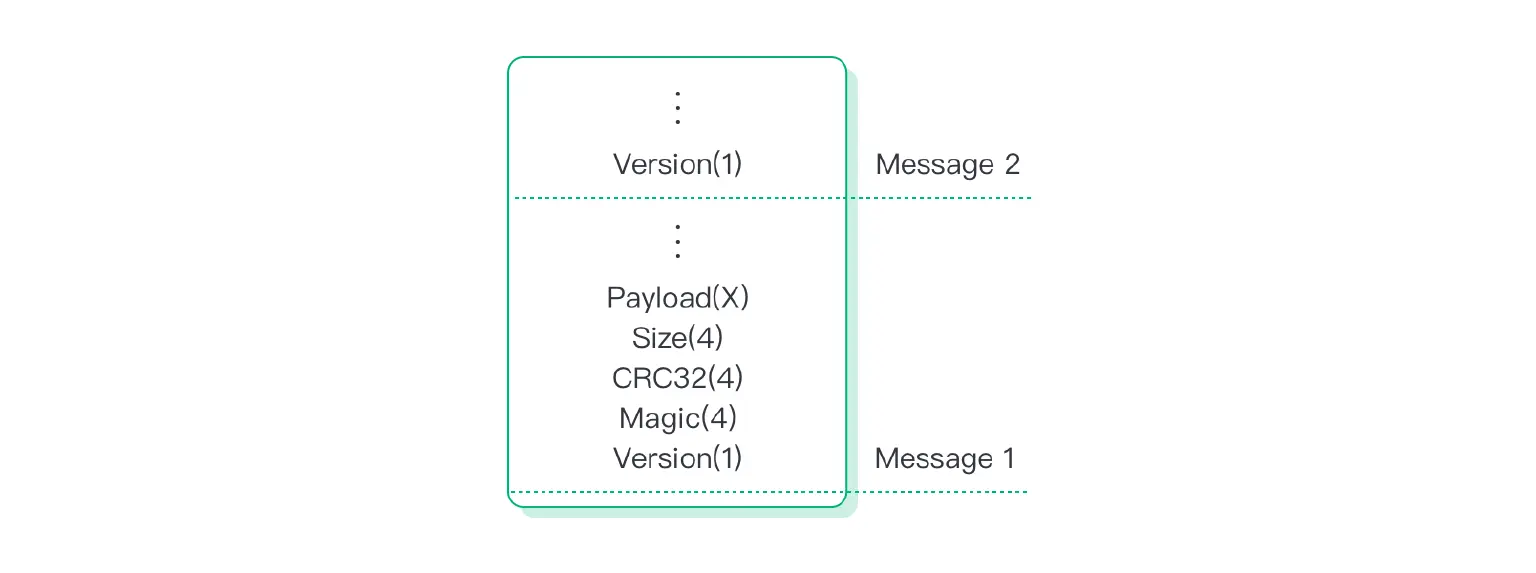
In case the magic number is not found (at byte 2-5), or the payload checksum does not match, corruption is detected. All the messages starting from the corrupted are discarded (file is truncated).
Overload Protection
Like any other queuing solution, if the incoming rate is higher than the outgoing, it will eventually overflow no matter how great capacity the queue has.
In order to protect EMQX nodes from running out of allocatable RAM or disk space, there are mechanisms to protect the system by discarding the oldest messages.
Per Buffer Total Bytes Limit
For each buffer, there is a configurable limit of total number of bytes allowed to be accumulated. The default is 2GB.
One thing worth noting is the size of each message to be buffered is only an estimation, also, in order not to end up having empty segments, the size limit check is only done after at least one message is appended.
After each append, the total bytes check is performed, and the overflowed part will be popped out and dropped. Again, it always pops out at least one message, so there can be more bytes popped than overflowed bytes.
We may need to do some math when configuring the capacity for each buffer, there is a simple formula for it.
TotalBytesLimit = TotalAllocatableBytes / NumberOfQueues
For example, when planning for a Kafka producer using the disk mode buffering for bridging data to a Kafka topic having k partitions, if the total disk space that can be allocated for buffering is v, then the capacity for each queue should be v/k.
Drop on High Load
The total bytes limit configuration is a good option to protect the system from consuming too much RAM when running in “Memory Only” mode. Also, a good way to protect it from taking up too much disk space when running in “Disk Mode”. However, the limit is per-Kafka partition, which means it requires some careful calculation and planning.
A more relaxed way to ensure RAM overload protection is to auto-adjust the limit.
EMQX provides a drop_if_highmem option in 4.4, and memory_overload_protection in 5.0 configuration for the Kafka data integration (disabled by default).
When enabled, after the system has reached the ‘high load’ threshold, when appending to the queue, at least the same amount of bytes will be popped out from the head of the queue and dropped. The exact amount of bytes depends on the boundary alignment of the queue items.
Summary
By introducing ReplayQ as the buffer layer in EMQX Rule-Engine data integration, it can help to improve EMQX’s robustness, make the data pipeline more resilient to network disturbances and the target service downtimes.