Reaching 100M MQTT connections with EMQX 5.0

The ever-increasing scale of IoT device connections and deployments requires IoT messaging platforms to be massively scalable and robust at scale. To stress test the scalability of the MQTT messaging broker EMQX, we established 100 million MQTT connections to the clusters of 23 EMQX nodes to see how EMQX performs.
In this test, each MQTT client subscribed to a unique wildcard topic, which requires more CPU resources than a direct topic. When publishing, we chose a 1-to-1 publisher-subscriber topology and reached 1 M messages processed per second. We also compared how the maximum subscription rate varies as the cluster size increases when we were using two different database backends, RLOG DB and Mnesia. Here we detail our setup and some of the challenges we faced along the way.
Introduction
EMQX is an open-source, highly scalable, and distributed MQTT messaging broker written in Erlang/OTP that can support millions of concurrent clients. As such, there is a need to persist and replicate various data among the cluster nodes. For example: MQTT topics and their subscribers, routing information, ACL rules, various configurations, and many more. Since its beginning, EMQX has used Mnesia as the database backend for such needs.
Mnesia is an embedded ACID distributed database that comes with Erlang/OTP. It uses a full-mesh peer-to-peer Erlang distribution for transaction coordination and replication. Because of this characteristic, it has trouble scaling horizontally: the more nodes and replicas of the date there are, the bigger is the overhead for write-transaction coordination and the bigger is the risk of split-brain scenarios.
In EMQX 5.0, we attempted to mitigate this issue in a new DB backend type called RLOG (as in replication log), which is implemented in Mria. Mria is an extension to the Mnesia database that helps it scale horizontally by defining two types of nodes: i) core nodes, which behave as usual Mnesia nodes and participate in write transactions; ii) replicant nodes, which do not take part in transactions and delegate those to core nodes, while keeping a read-only replica of the data locally. This helps to reduce the risk of split-brain scenarios and lessens the coordination needed for transactions, since fewer nodes participate in it, while keeping read-only data access fast, since data is available locally for reading in all nodes.
In order to be able to use this new DB backend by default, we needed to stress test it and verify that it does indeed scale well horizontally. For that end, we performed tests in which a 23 node EMQX cluster sustained 100 million concurrent connections, divided in half between publishers and subscribers, and published messages in a one-to-one fashion. We also compared the RLOG DB backend to the conventional Mnesia one, and confirmed that RLOG can indeed sustain higher arrival rates than Mnesia.
How we tested the scalability of mqtt broker
For deploying and running our cluster tests, we used AWS CDK, which allowed us to experiment with different instance types and numbers, and also trying out different development branches of EMQX. You can checkout our scripts in this Github repo. In our load generator nodes ("loadgens" for short), we used our emqtt-bench tool to generate the connection / publishing / subscribing traffic with various options. EMQX's Dashboard and Prometheus were used for monitoring the progress of the test and the instances' health.
We've experimented gradually with various instance types and numbers, and in the last runs we've settled on using c6g.metal instances for both EMQX nodes and loadgens, and the "3+20" topology for our cluster: 3 nodes of type "core", which take part in write transactions, and 20 nodes of type "replicant", which are read-only replicas and delegate writes to the core nodes. As for our loadgens, we observed that publisher clients required quite a bit more resources than subscribers. For only connecting and subscribing 100 million connections, only 13 loadgen instances were needed; for publishing as well, we needed 17 instances.
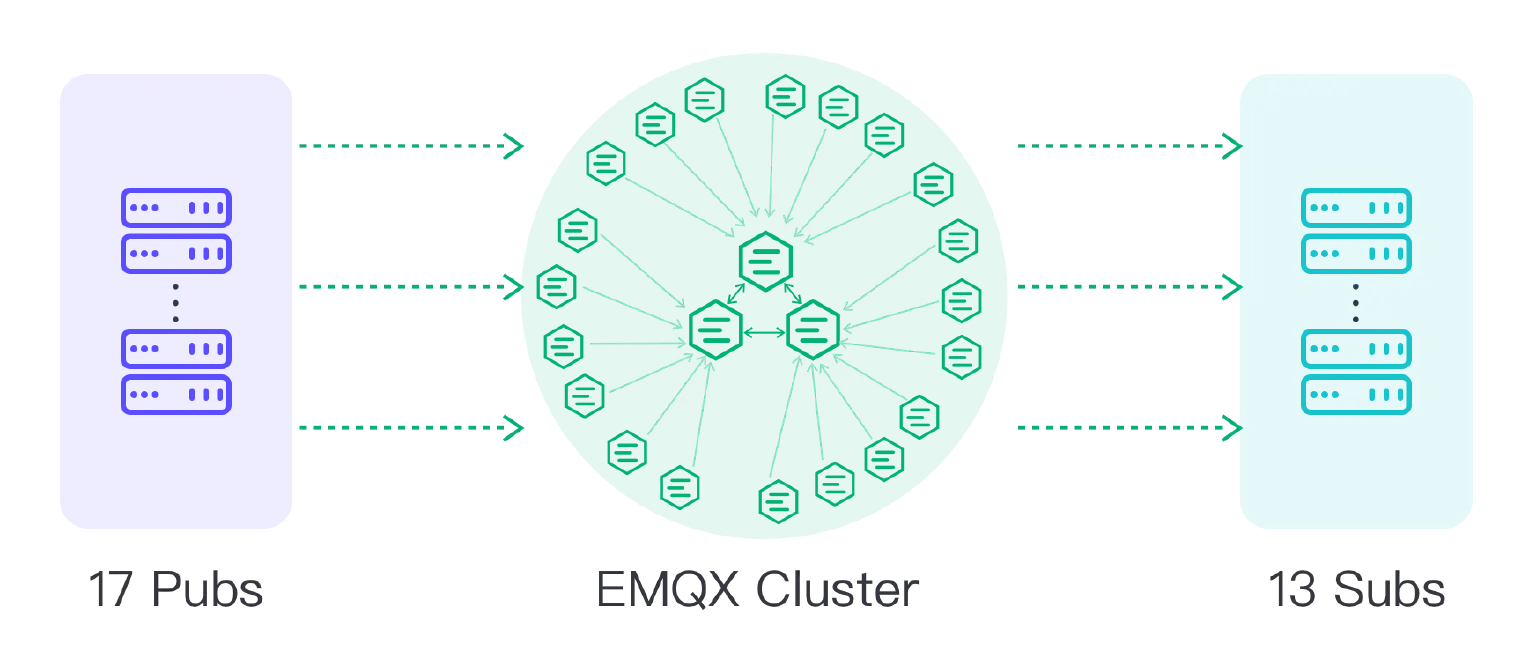
We did not use any load-balancers for those tests, and loadgens connected directly to each node. To allow core nodes to be dedicated solely for managing the database transactions, we did not make connections to them, and each loadgen client connected directly to each node in an evenly distributed fashion, so all nodes had about the same number of connections and resource usage. Each subscriber subscribed to a wildcard topic of the form bench/%i/# with QoS 1, where %i stands for a unique number per subscriber, and each publisher published with QoS 1 to a topic of the form bench/%i/test, with the same %i as the subscribers. That ensured that for each publisher there was exactly one subscriber. The size of the payload in the messages was always 256 bytes.
In our tests, we first connected all our subscribers clients, and only then started to connect our publishers. Only after all publishers were connected they started to publish each every 90 s. The rate at which both subscribers and publishers connected to the brokers was 16,000 connections / s for the 100 M connection test reported here, although we believe that the cluster can sustain an even higher connection rate.
Challenges along the way
As we experimented with such large volumes of connections and throughput, we've encountered several challenges along the way, investigated and improved performance bottlenecks. For tracking down memory and CPU usage in Erlang processes, system_monitor was quite a helpful tool, which is basically "htop for BEAM processes", allowing us to find processes with long message queues, high memory and/or CPU usage. It helped us perform a few performance tunings [1][2]3 in Mria after what we observed during the cluster tests.
In our initial tests with Mria, without going into too many details, the replication mechanism basically involved logging all transactions to a "phantom" Mnesia table, which was subscribed to by replicant nodes. This effectively generated a bit of network overhead between the core nodes because each transaction was essentially "duplicated". In our OTP fork, we added a new Mnesia module that allows us to capture all committed transaction logs more easily, removing the need for the "duplicate" writes and reducing network usage significantly, and allowing the cluster to sustain higher connection / transaction rates. While stressing the cluster further after those optimizations, we found new bottlenecks that prompted further performance tunings[4][5]6.
Even our benchmarking tool needed a few adjustments to help with such a large volume and rate of connections. Several quality-of-life improvements have been made[7][8][9]10, as well as a couple of performance optimizations[11]12. In our pub-sub tests, we even needed to use a special fork of it for the sole purpose of the test so that memory usage could be further lowered (not in the current master branch).
Results
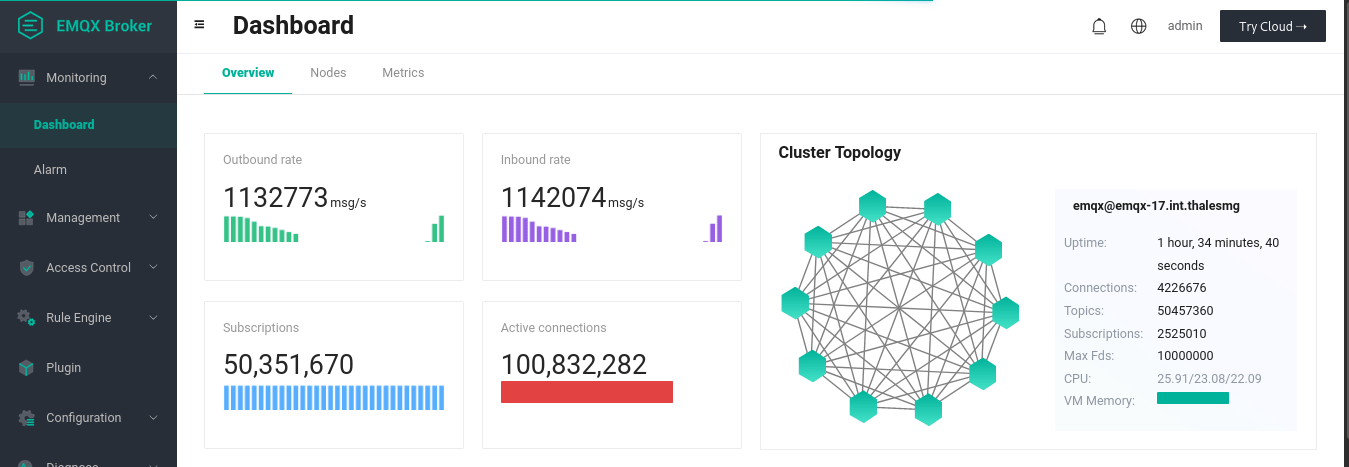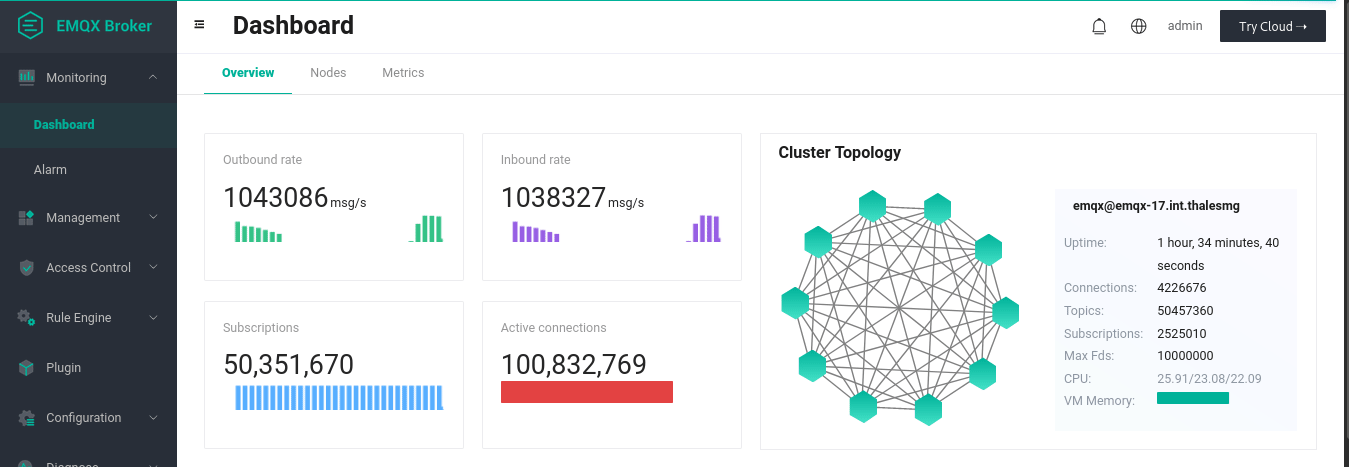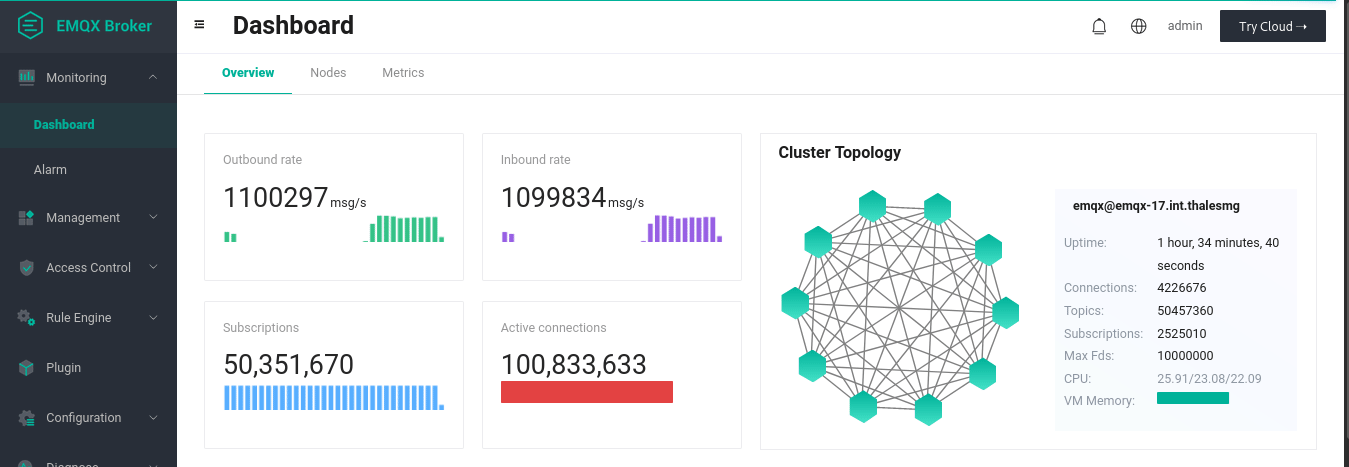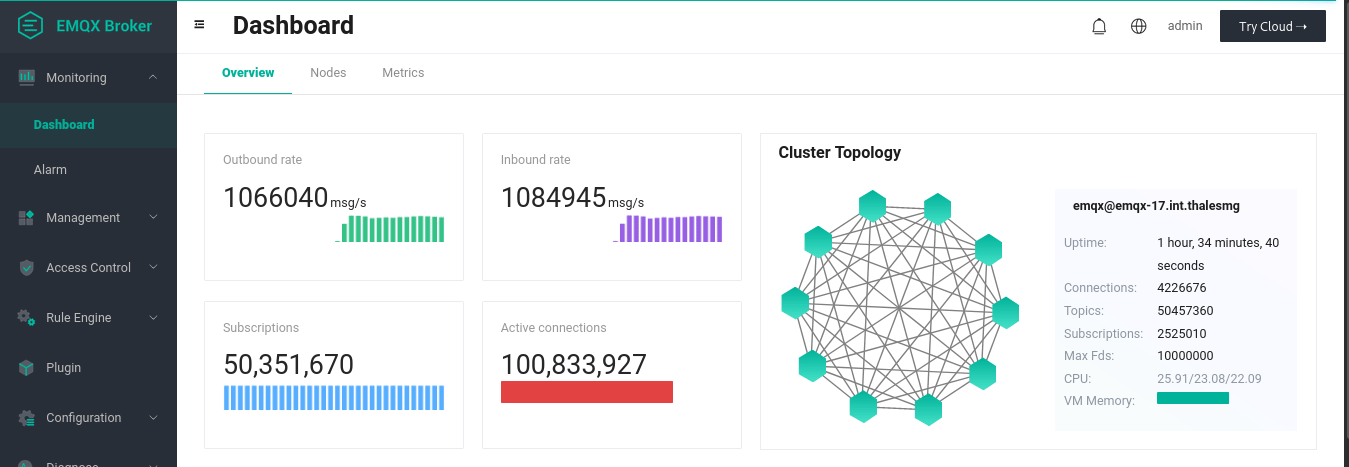
NOTE: In this test, all of the paired publishers and subscribers happened to reside in the same broker, which is not an ideal scenario close to real life use cases. The EMQX team is conducting more tests, and will follow up with more updates.
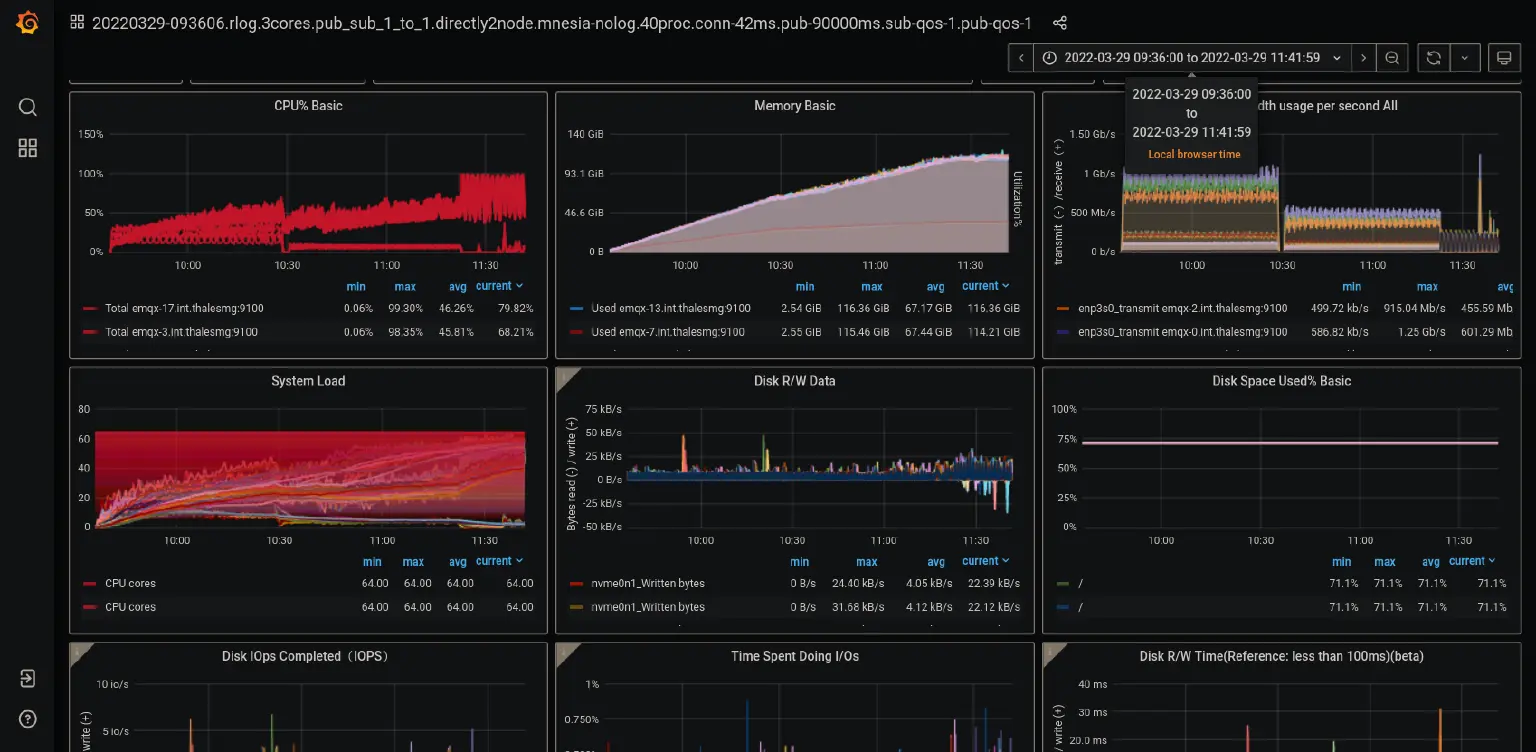
The animation above illustrates our final results for the 1-to-1 publish-subscribe tests. We established 100 million connections, 50 M of which were subscribers and 50 M were publishers. By publishing every 90 seconds, we see that average inbound and outbound rates of over 1 M messages per second are achieved. At the publishing plateau, each of the 20 replicant nodes (which, we remind, are the ones taking in connections) consumed on average 90 % of its memory (about 113 GiB), and around 97 % CPU during the publishing waves (64 arm64 cores). The 3 core nodes handling the transactions were quite idle in CPU (less than 1 % usage) and used up only 28 % of their memory (about 36 GiB). The network traffic required during the publishing waves of 256 bytes payloads was between 240 and 290 MB / s. The loadgens required almost all their memory (about 120 GiB) and their entire CPU during the publishing plateau.
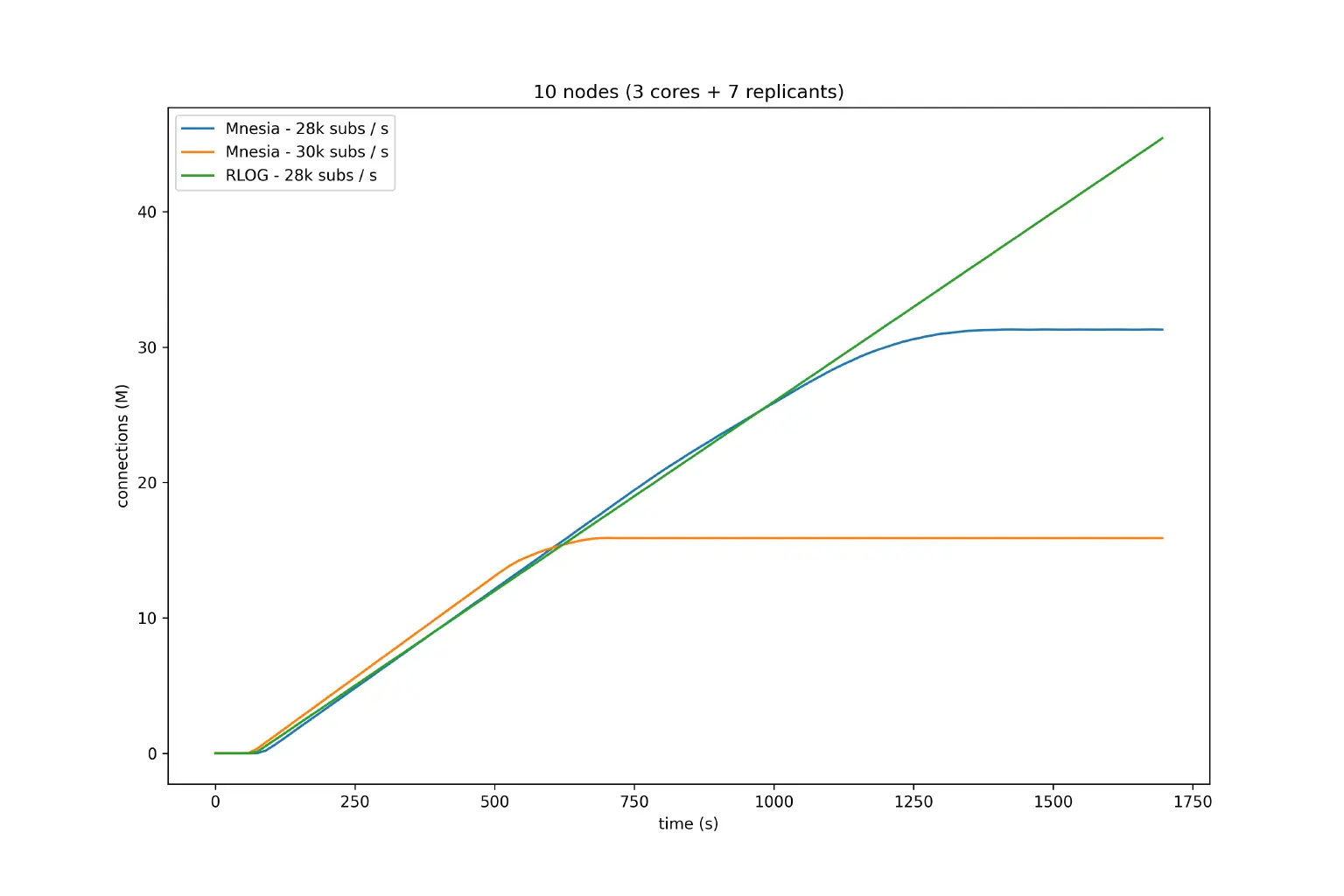
In order to fairly compare a RLOG cluster to an equivalent Mnesia cluster, we used another topology with fewer total connections: 3 core nodes + 7 replicants for RLOG, and a 10-node Mnesia cluster where only 7 of those took in connections. With such topology, we performed connections and subscriptions without publishing at different rates. The plot below illustrates our results. For Mnesia, the faster we try to connect and subscribe to the nodes, the more we observe a "flattening" behavior, where the cluster is not able to reach the target maximum number of connections, which is 50 million in those tests. For RLOG, we see that we can reach higher connection rates without the cluster exhibiting such flattening behavior. With that, we see that Mria using RLOG can perform better under higher connection rates than the older Mnesia backend.
Final remarks
After seeing those optimistic results, we believe that the RLOG DB backend offered by Mria is ready for production usage in EMQX 5.0. It is already the default DB backend in the current master branch.
References
1 - fix(performance): Move message queues to off_heap by k32 · Pull Request #43 · emqx/mria
3 - fix(mria_status): Remove mria_status process by k32 · Pull Request #48 · emqx/mria
4 - Store transactions in replayq in normal mode by k32 · Pull Request #65 · emqx/mria
5 - feat: Remove redundand data from the mnesia ops by k32 · Pull Request #67 · emqx/mria
6 - feat: Batch transaction imports by k32 · Pull Request #70 · emqx/mria
7 - feat: add new waiting options for publishing by thalesmg · Pull Request #160 · emqx/emqtt-bench
8 - feat: add option to retry connections by thalesmg · Pull Request #161 · emqx/emqtt-bench
9 - Add support for rate control for 1000+ conns/s by qzhuyan · Pull Request #167 · emqx/emqtt-bench
10 - support multi target hosts by qzhuyan · Pull Request #168 · emqx/emqtt-bench
11 - feat: bump max procs to 16M by qzhuyan · Pull Request #138 · emqx/emqtt-bench
12 - feat: tune gc for publishing by thalesmg · Pull Request #164 · emqx/emqtt-bench